Multivariate Visualizations + Idea Lab
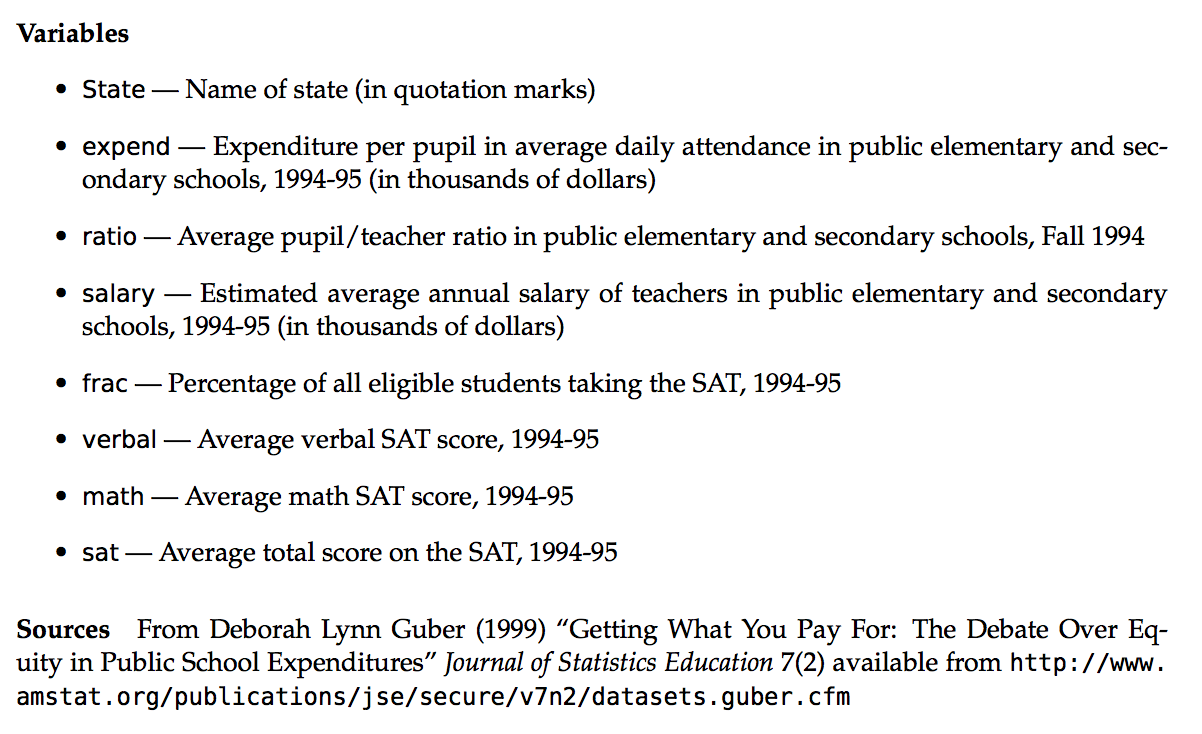
Data: Codebook
Univariate Density
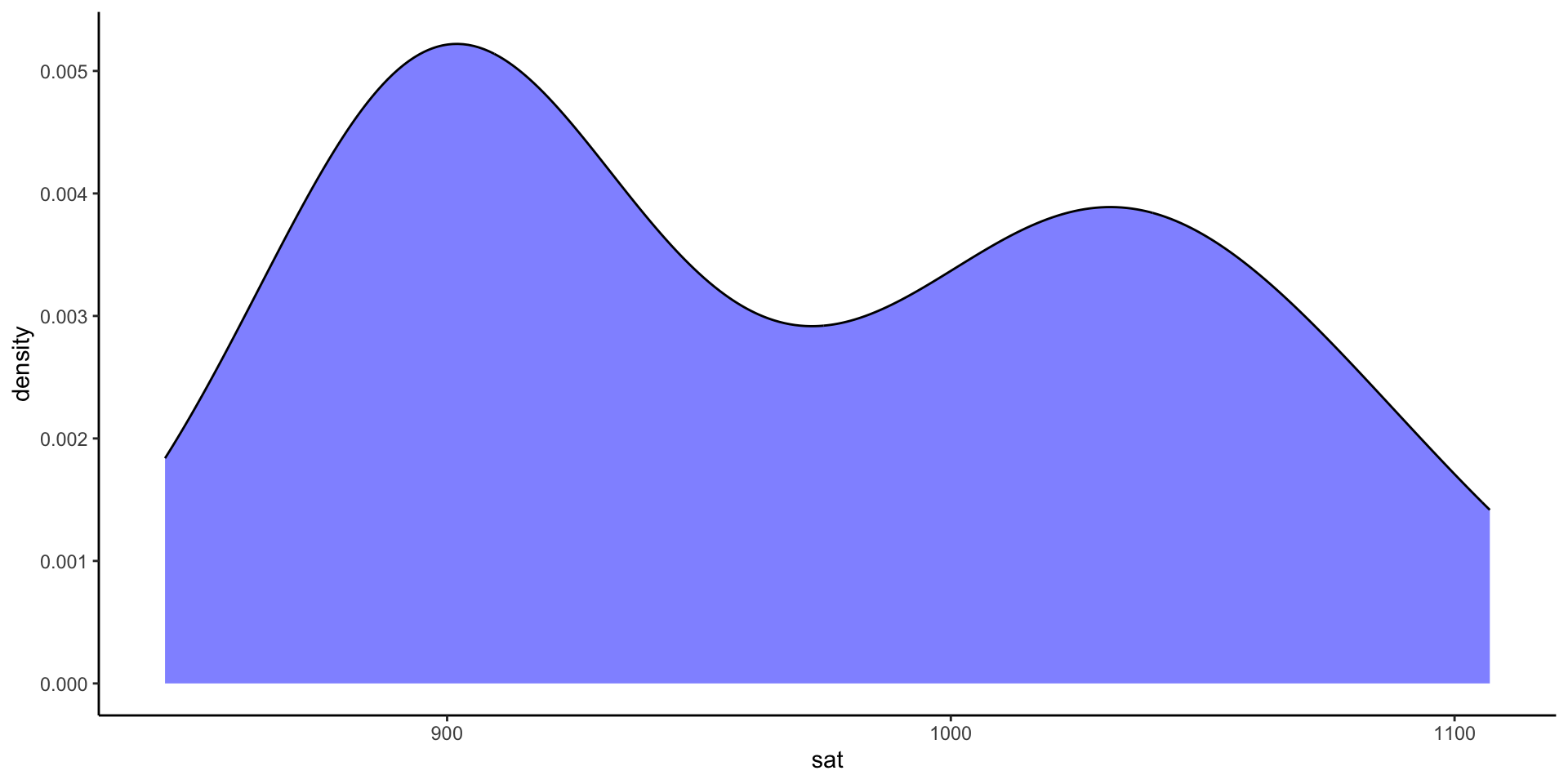
Variability in average SAT scores from state to state:
Bivariate Scatterplot
What degree do per pupil spending (expend) and teacher salary explain this variability?
ggplot(education, aes(y = sat, x = salary)) +
geom_point() +
geom_smooth(se = FALSE, method = "lm") + theme_classic() +
theme(text = element_text(size=20))
ggplot(education, aes(y = sat, x = expend)) +
geom_point() +
geom_smooth(se = FALSE, method = "lm") + theme_classic() +
theme(text = element_text(size=20))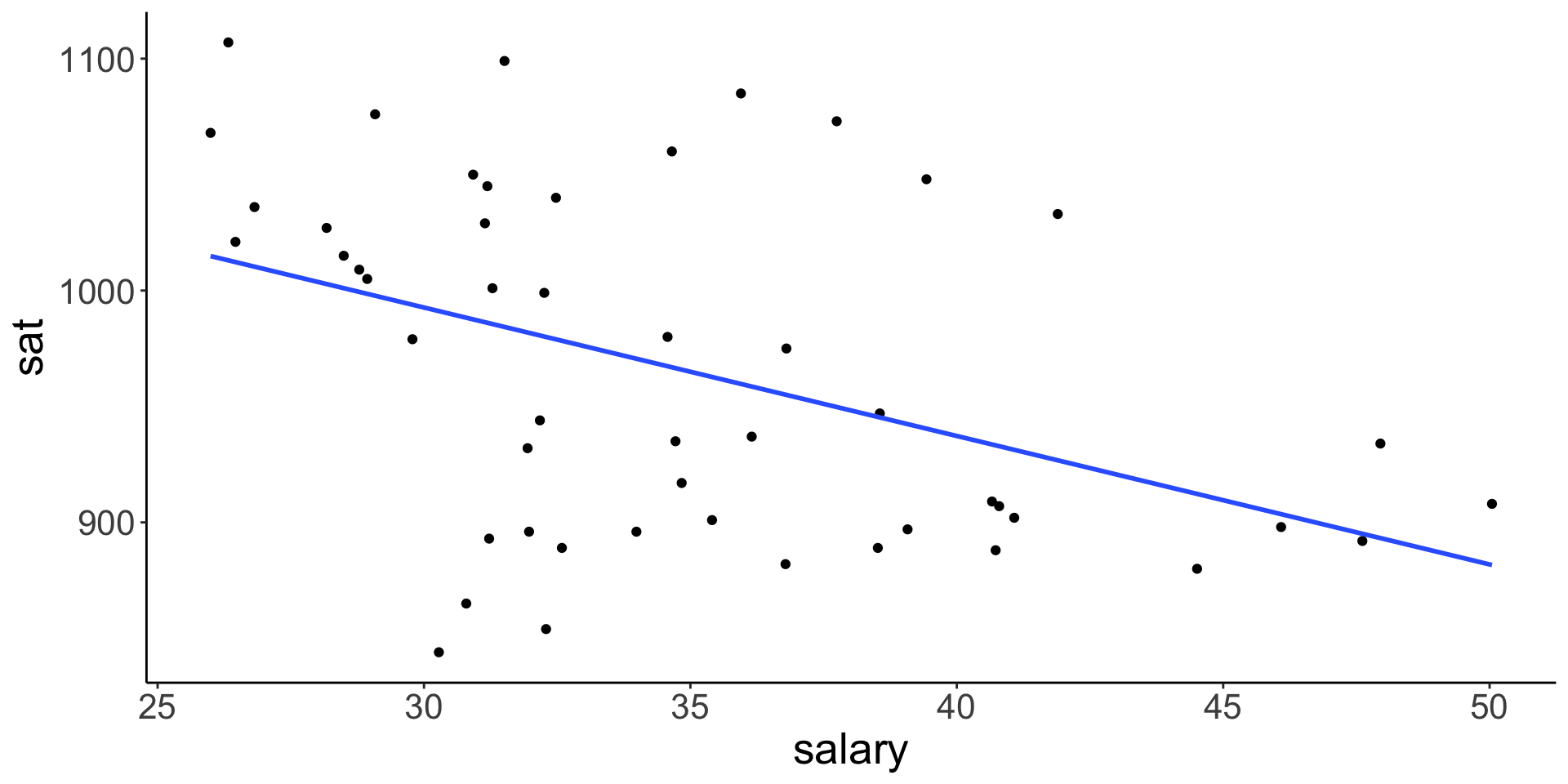
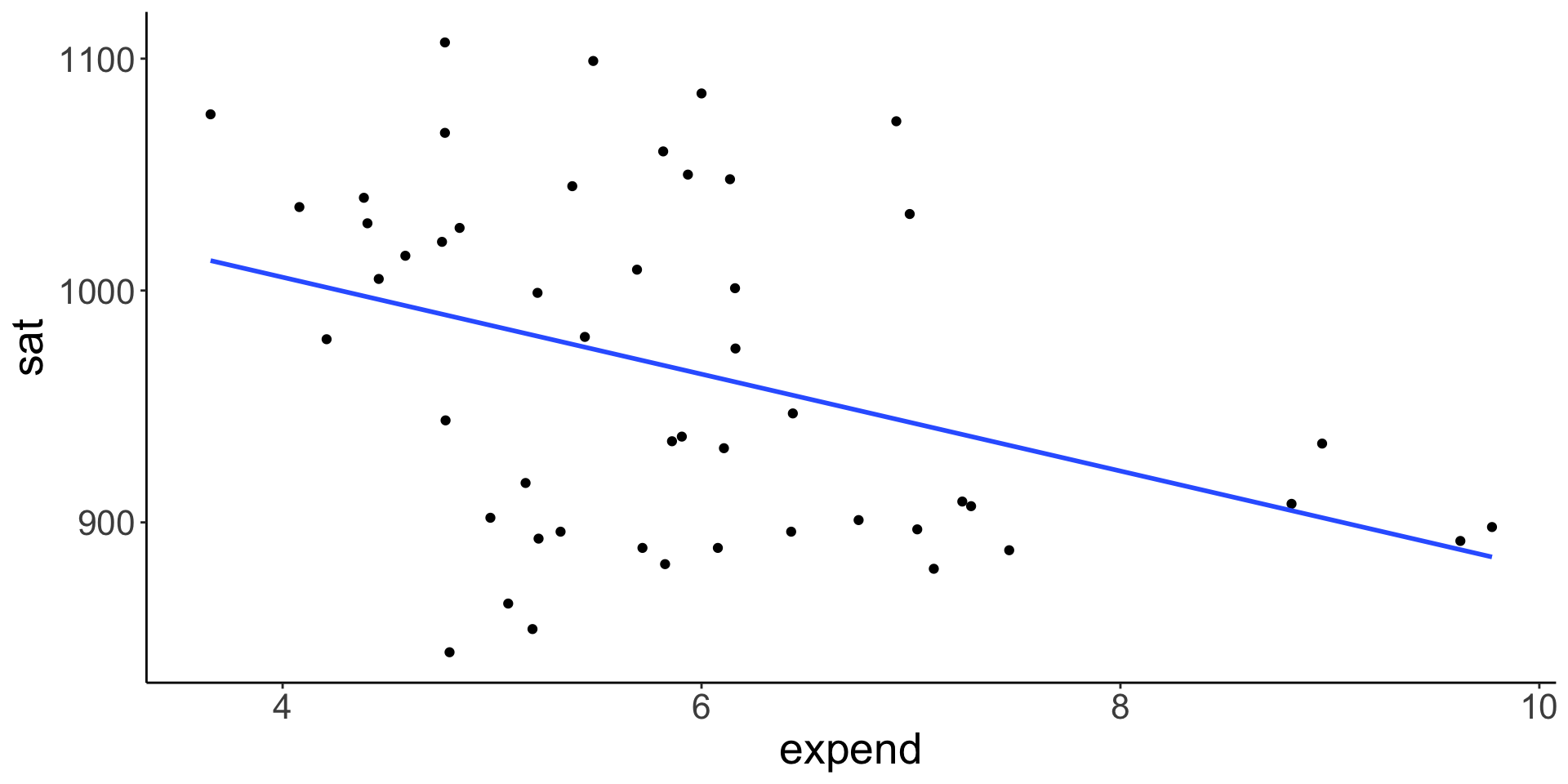
Is there anything that surprises you in the above plots? What are the relationship trends? Discuss as a group.
Example: Three Variables
Let’s make a single scatterplot visualization that demonstrates the relationship between sat, salary, and expend.
Thoughts:
1. We could use the color or size aesthetics to incorporate the expenditure data.
2. Include some model smooths with geom_smooth() to help highlight the trends.
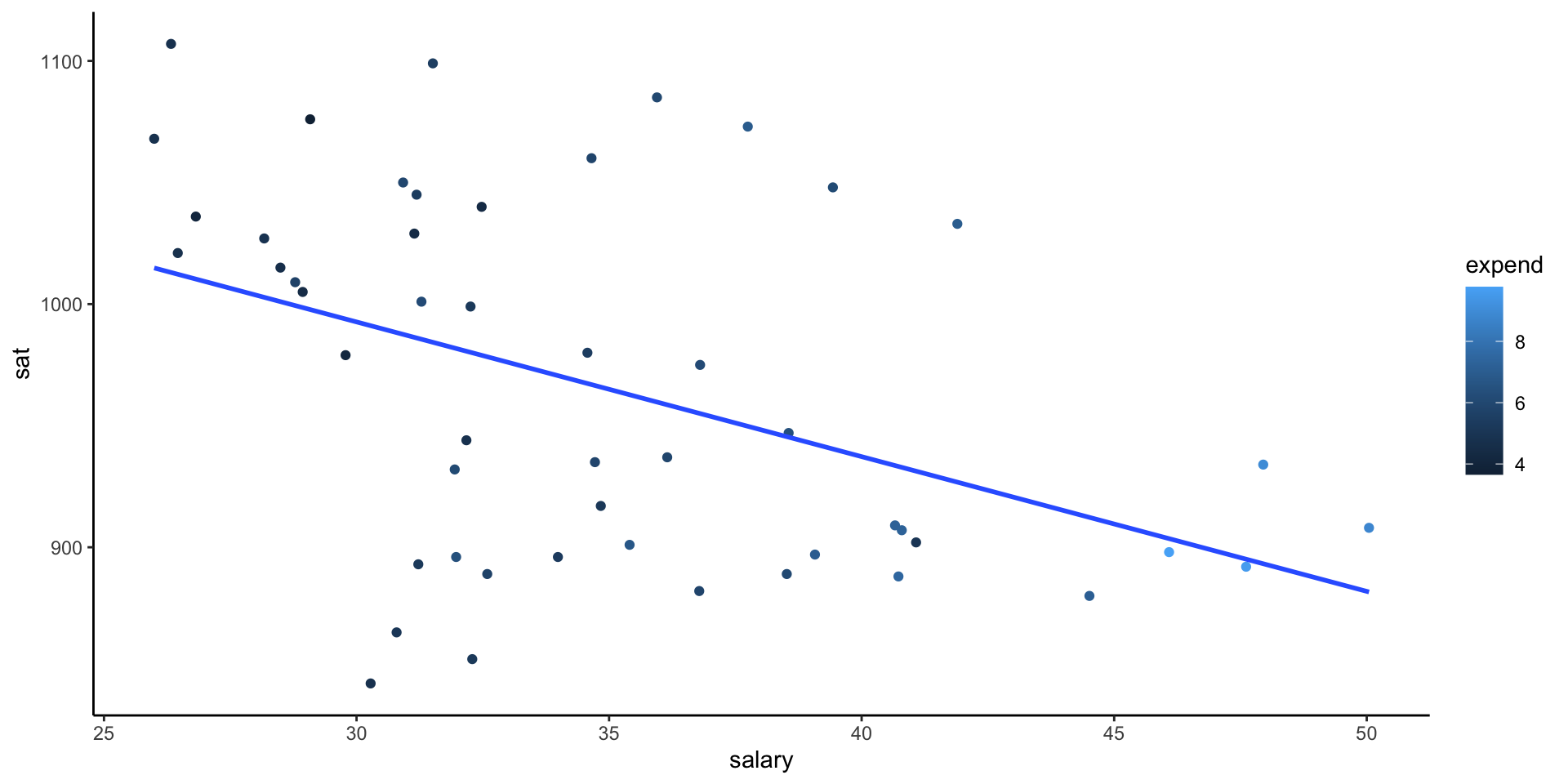
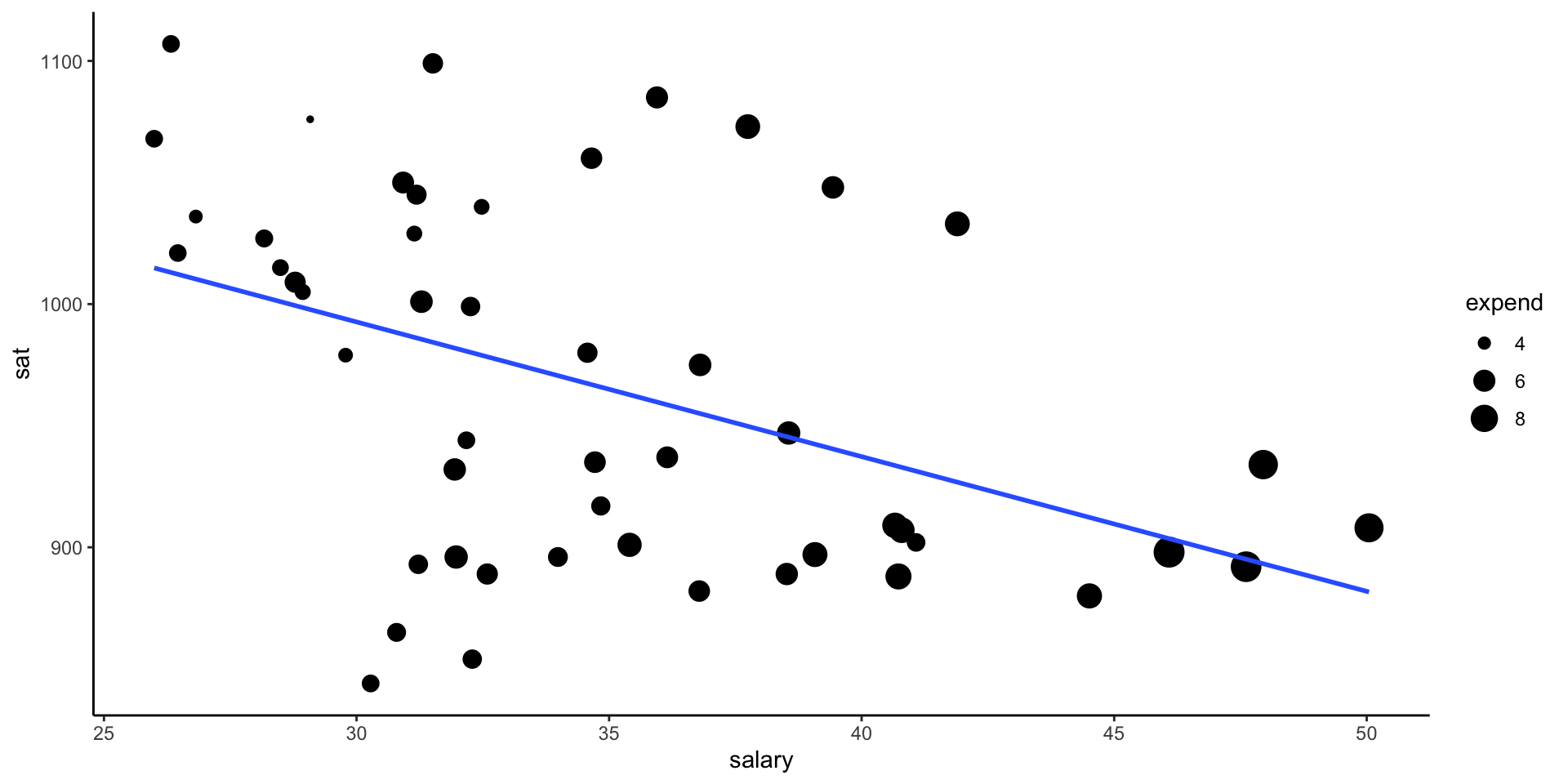
Example: Three Variables
Another option!
Categorize your 3rd Quantitative Variable!
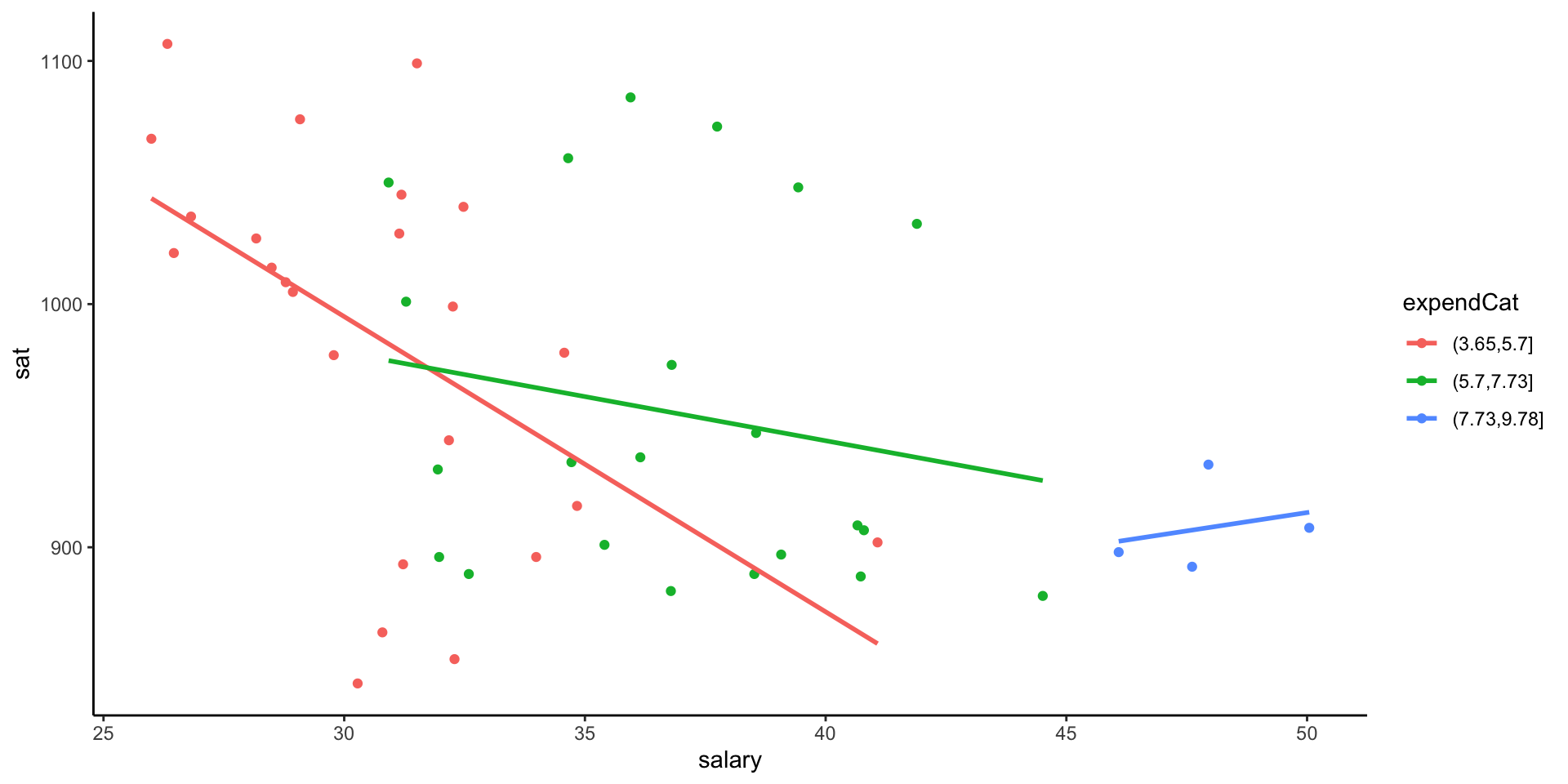
Example: Fraction who take SAT
The fracCat variable in the education data categorizes the fraction of the state’s students that take the SAT into low (below 15%), medium (15-45%), and high (at least 45%).
- Make a univariate visualization of the
fracCatvariable to better understand how many states fall into each category.
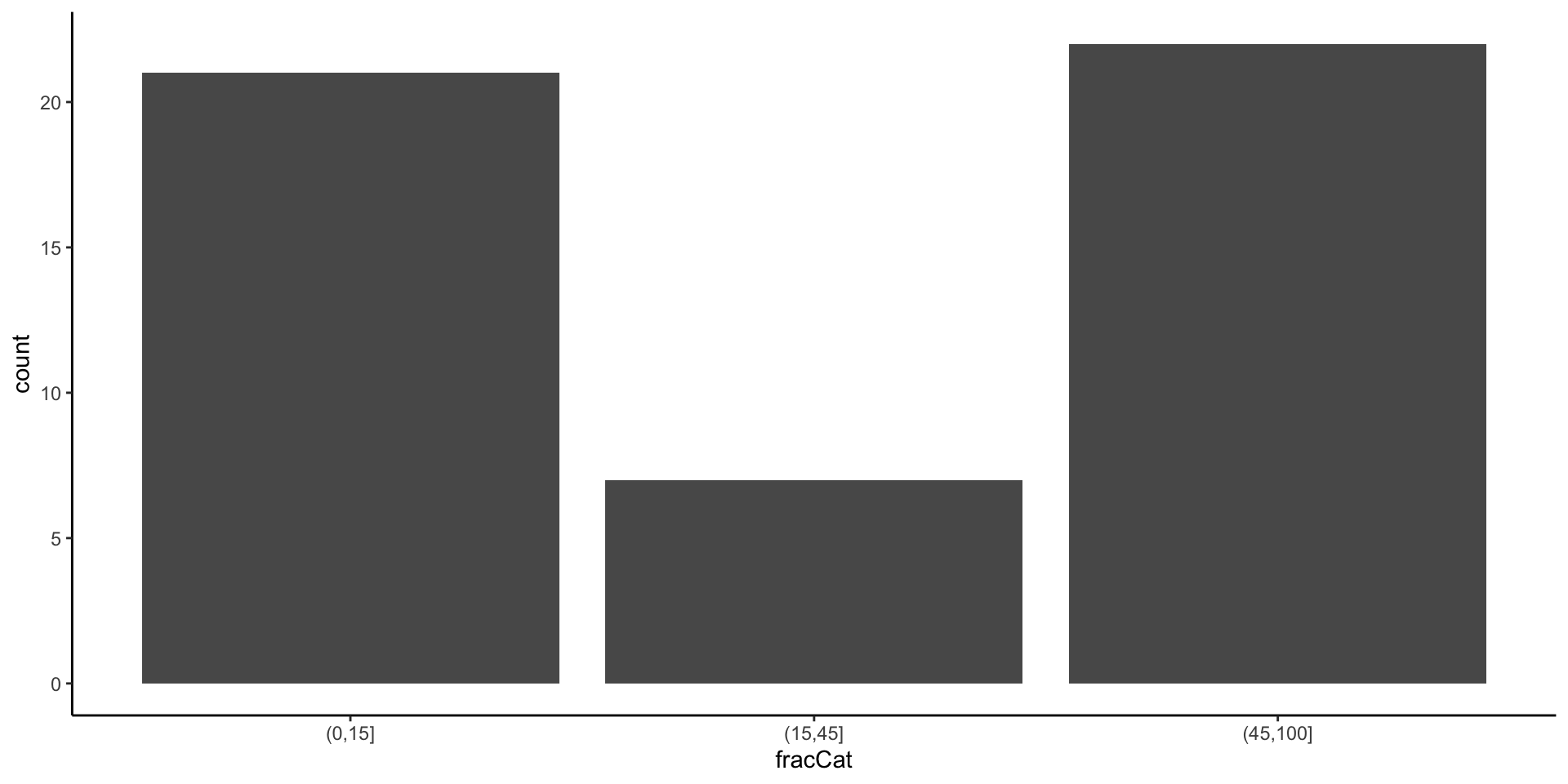
Example: Fraction who take SAT
- Make a bivariate visualization that demonstrates the relationship between
fracCatandsat. What story does your graphic tell?
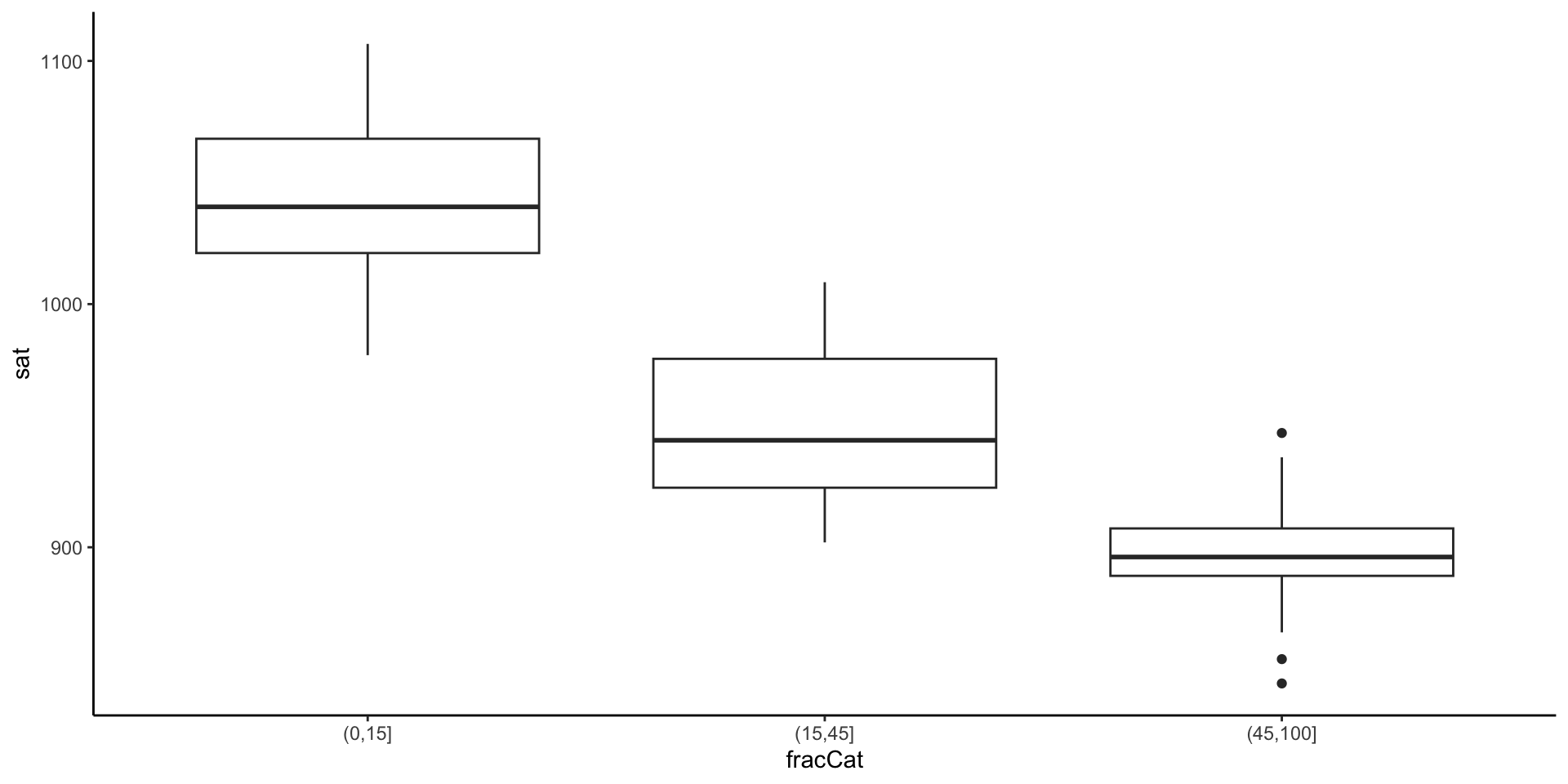
Example: Fraction who take SAT
- Make a trivariate visualization that demonstrates the relationship between
fracCat,sat, andexpend. IncorporatefracCatas the color of each point, and use a single call togeom_smoothto add three trendlines (one for eachfracCat). What story does your graphic tell?
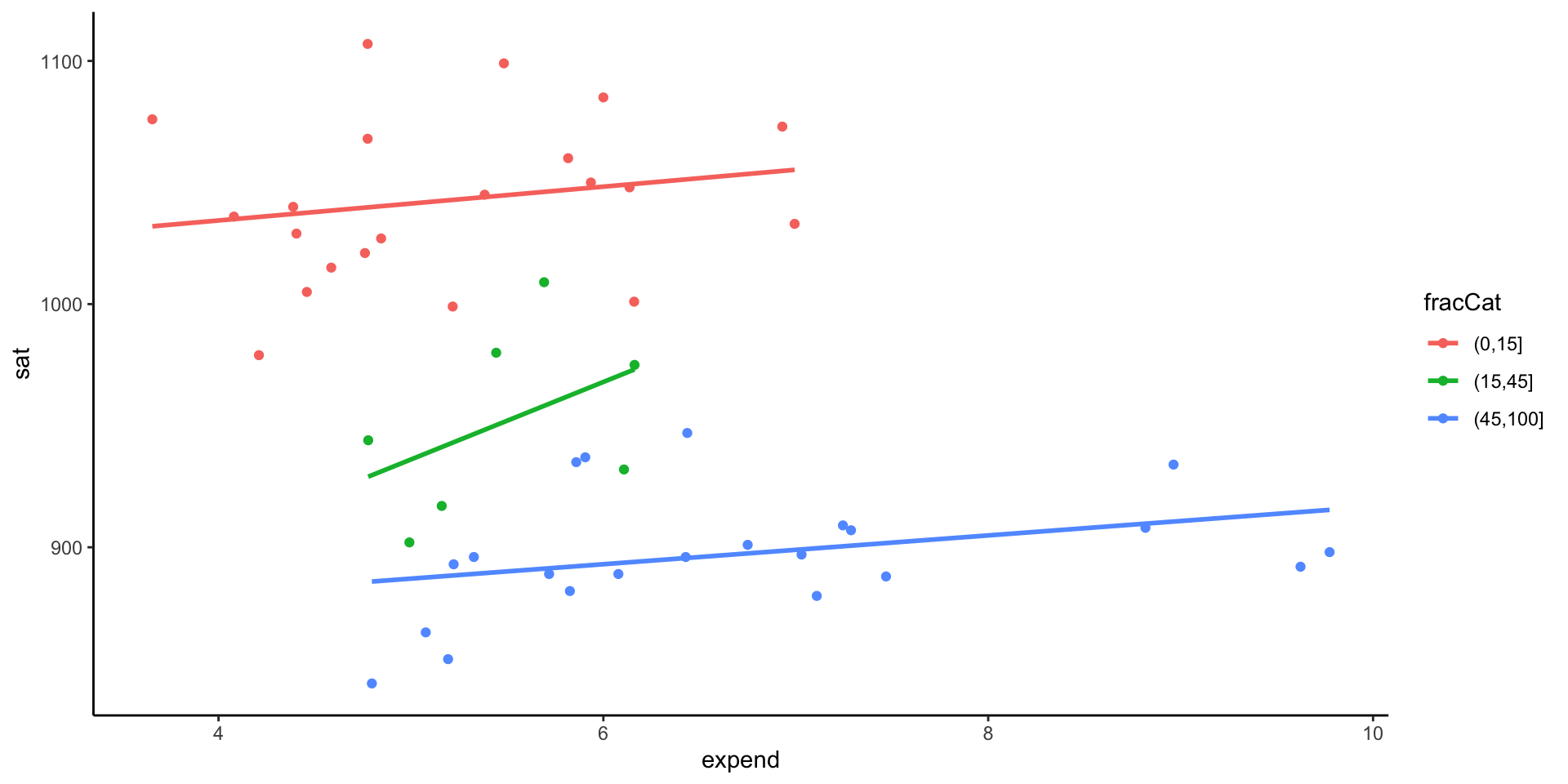
Handmade Visualizations - Data
| Name | Area (acres) | Max depth (feet) |
Watershed area (acres) |
Chain of lakes | Longitude | Latitude | City |
| Bde Maka Ska | 401 | 87 | 2992 | Yes | -93.311883 | 44.941966 | Minneapolis |
| Lake Harriet | 335 | 85 | 1139 | Yes | -93.304514 | 44.921725 | Minneapolis |
| Lake Nokomis | 204 | 33 | 869 | No | -93.241582 | 44.908678 | Minneapolis |
| Cedar Lake | 170 | 51 | 1956 | Yes | -93.321751 | 44.959361 | Minneapolis |
| Lake of the Isles | 109 | 31 | 735 | Yes | -93.306507 | 44.955482 | Minneapolis |
| Lake Hiawatha | 54 | 33 | 1734 | No | -93.236044 | 44.920906 | Minneapolis |
| Lake Como | 71 | 15 | 1783 | No | -93.140153 | 44.979637 | St Paul |
| Lake Phalen | 198 | 91 | 14720 | No | -93.053102 | 44.986744 | St Paul |