| sid | sessionID | grade |
|---|---|---|
| S31842 | session2207 | B+ |
| S32436 | session3172 | S |
| S31671 | session3435 | A- |
| S31929 | session3512 | NC |
Joining Data
Joins
Definition
A join is a verb that means to combine two data tables.
- These tables are often called the left and the right tables.
. . .
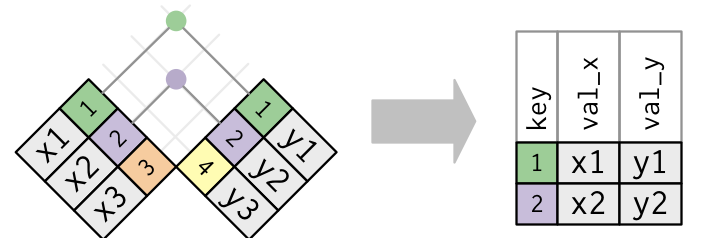
Kinds of Joins
All joins involve establishing a correspondence — a match — between each case in the left table and zero or more cases in the right table.
The various joins differ in how they handle multiple matches or missing matches.
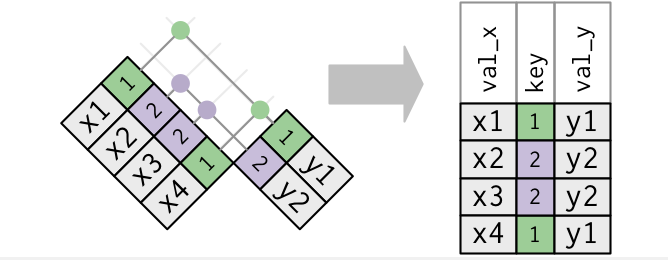
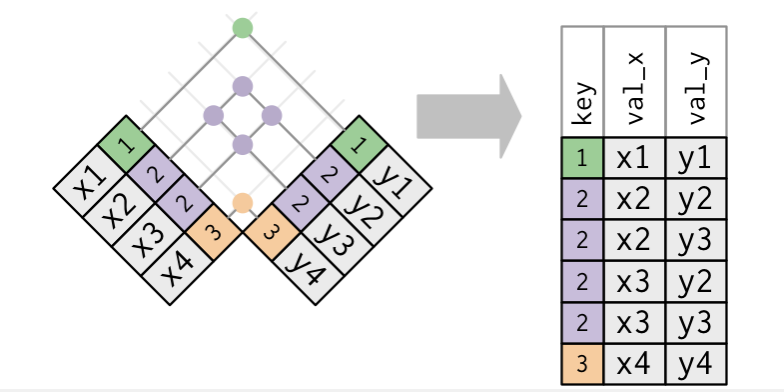
Mutating Joins
A mutating join allows you to combine variables from two tables. It first matches observations by their keys, then copies across variables from one table to the other.
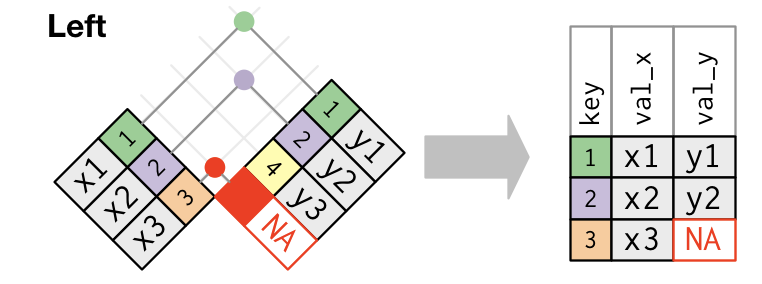
left_join(): the output has all cases from the left, regardless if there is a match in the right, but discards any cases in the right that do not have a match in the left.![]()
inner_join(): the output has only the cases from the left with a match in the right.![]()
full_join(): the output has all cases from the left and the right. This is less common than the first two join operators.![]()
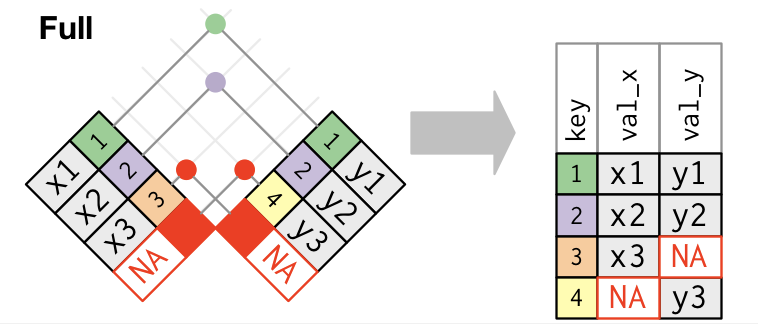
For all of these mutating joins, if a row in the left matches multiple rows in the right, all the rows in right will be returned once for each matching row in the left.
Filtering Joins
Filtering joins affect the observations, not the variables.
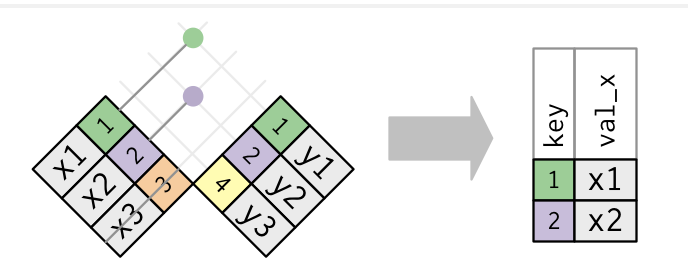
semi_join(): discards any cases in the left table that do not have a match in the right table. If there are multiple matches of right cases to a left case, it keeps just one copy of the left case.![]()
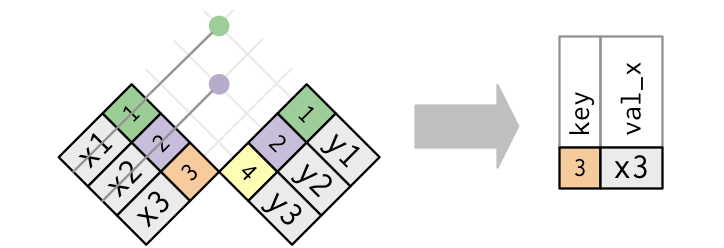
anti_join(): discards any cases in the left table that have a match in the right table.![]()
After Class
Work on the 6 exercises to turn in for Assignment 6 + 3 exercises from Reshaping (pivot_wider, pivot_longer).
These exercises help you deepen your understanding of
- Data Wrangling (6 Main Verbs)
- Data Visualization (including Spatial Viz)