thigh hip age abdomen knee chest
-0.11301249 -0.10648937 -0.05853538 -0.02173587 0.02345904 0.05838830
biceps ankle weight forearm wrist neck
0.07441696 0.07920867 0.11228791 0.16968040 0.28967468 0.29147610
height
1.00000000 Model Selection
Notes - Model Selection
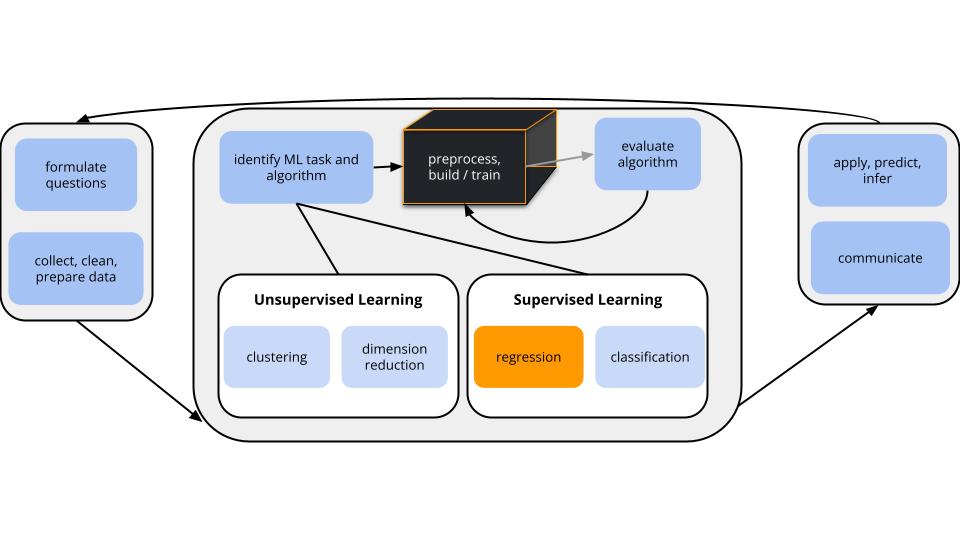
CONTEXT
world = supervised learning
We want to model some output variable \(y\) using a set of potential predictors \((x_1, x_2, ..., x_p)\).task = regression
\(y\) is quantitativemodel = linear regression
We’ll assume that the relationship between \(y\) and (\(x_1, x_2, ..., x_p\)) can be represented by\[y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + ... + \beta_p x_p + \varepsilon\]
After Class
Finishing the activity
- If you didn’t finish the activity, no problem! Be sure to complete the activity outside of class, review the solutions in the course website, and ask any questions on Slack or in office hours.
Continue to check in on Slack. I’ll be posting announcements there from now on.
Upcoming due dates
Today by 11:59pm: Homework 2
Tuesday, 10 minutes before your section: Checkpoint 5.
Tuesday 2/13: Homework 3
- Next Tuesday we’ll cover more of the concepts covered on this HW.
- Using Slack, invite others to work on homework with you.
- Pass/fail, limited revisions,
- Deadline is so we can get timely feedback to you, let me know if you cannot make deadline (let me know what day you’ll finish)
- Next Tuesday we’ll cover more of the concepts covered on this HW.