LASSO
Announcements
- Wednesday at 12-1pm in OLRI 250 - MSCS Talk
- Ethics in Predictive Mental Health Applications: Building Tools to Interrogate our own Stances by Leah Ajmani

- Thursday at 11:15am - MSCS Coffee Break
- Smail Gallery
- On Thursday, I will assign you groups for ~2.5 weeks
- If working with someone in class would be a barrier to your learning, let me know.
- Check out this Minnesota Public Radio (MPR) interview on Can AI replace your doctor?! It’s a discussion of AI / machine learning in medicine. NOTE: ML is a subset of AI. (image from Wiki)

- Now that we’re on MPR, journalist David Montgomery used R for data analysis and visualizations using this custom ggtheme to make visuals for MPR. To create a custom ggtheme, check out https://themockup.blog/posts/2020-12-26-creating-and-using-custom-ggplot2-themes/.
Notes - LASSO
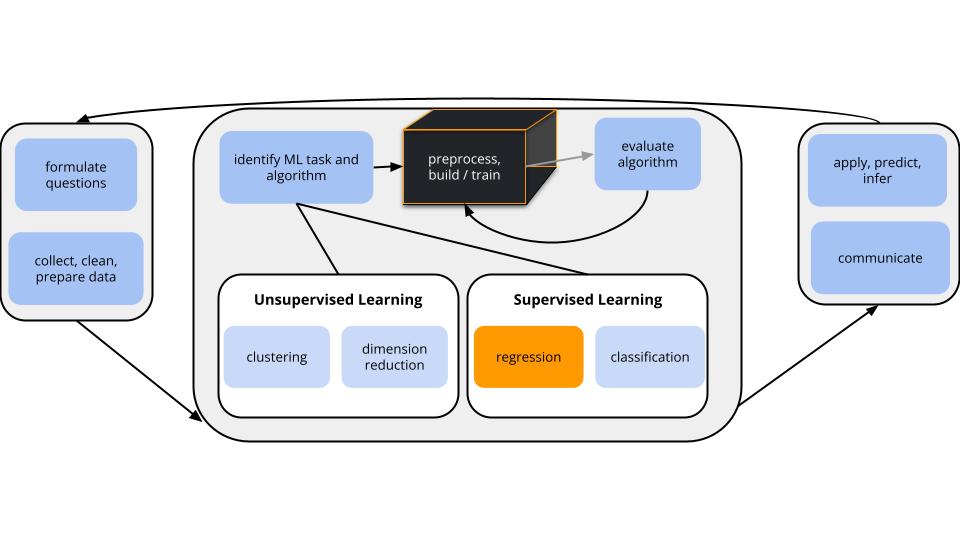
CONTEXT
world = supervised learning
We want to model some output variable \(y\) using a set of potential predictors \((x_1, x_2, ..., x_p)\).task = regression
\(y\) is quantitativemodel = linear regression
We’ll assume that the relationship between \(y\) and (\(x_1, x_2, ..., x_p\)) can be represented by\[y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + ... + \beta_p x_p + \varepsilon\]
- estimation algorithm = LASSO (instead of Least Squares)
After Class
- Finish the activity, check the solutions, and reach out with questions.
- There’s an R code reference section at the end, and optional R code tutorial videos posted for today’s material.
- If you’re curious, there’s an optional “deeper learning” section below that presents two other shrinkage algorithms that we won’t cover in this course.
- Continue to check in on Slack. I’ll be posting announcements there from now on.
Upcoming due dates
Nothing due Thursday
Due next Tuesday:
- Homework 3 (now posted)
- Checkpoint 6 (will be posted Thursday)