KNN & Bias Variance Tradeoff
As we gather
- Sit with your group (from last Thursday).
- Re-introduce yourselves!
- Discuss: What is your favorite thing at / about Cafe Mac?
- Open today’s Rmd.
- Install the
shiny and kknn packages if you haven’t already.
Announcements
- Thursday at 11:15am - MSCS Coffee Break
- When copying code, pause to make sure you adjust the values/inputs to the data you are working with and my instructions.
- HW3: When fitting LASSO to spotify data, if you don’t make adjustments to the code then the chosen lambda for the “final” model should cause you to pause.
- Knowing what the assumptions/decisions are being made for each chunk of code is important so that you can adjust those assumptions.
Notes - K Nearest Neighbors (KNN)
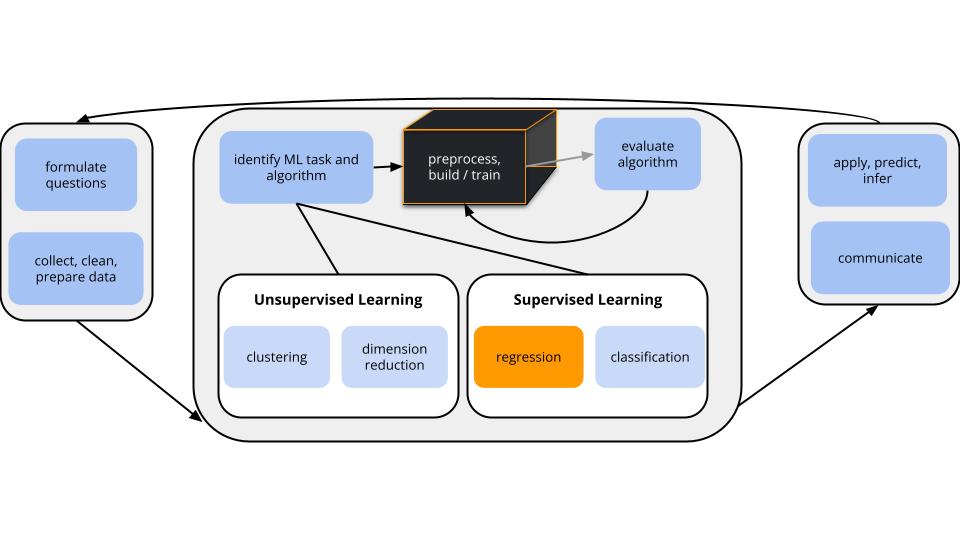
CONTEXT
world = supervised learning
We want to model some output variable \(y\) using a set of potential predictors \((x_1, x_2, ..., x_p)\).
task = regression
\(y\) is quantitative
(nonparametric) algorithm = K Nearest Neighbors (KNN)
Our usual parametric models (eg: linear regression) are too rigid to represent the relationship between \(y\) and our predictors \(x\). Thus we need more flexible nonparametric models.
Notes - KNN Regression
Goal
Build a flexible regression model of a quantitative outcome \(y\) by a set of predictors \(x\),
\[y = f(x) + \varepsilon\]
Idea
Predict \(y\) using the data on “neighboring” observations. Since the neighbors have similar \(x\) values, they likely have similar \(y\) values.
Algorithm
For tuning parameter K, take the following steps to estimate \(f(x)\) at each set of possible predictor values \(x\):
- Identify the K nearest neighbors of \(x\) with respect to Euclidean distance.
- Observe the \(y\) values of these neighbors.
- Estimate \(f(x)\) by the average \(y\) value among the nearest neighbors.
Output
KNN does not produce a nice formula for \(\widehat{f}(x)\), but rather a set of rules for how to calculate \(\widehat{f}(x)\).
Small Group Discussion: Recap Video
EXAMPLE 1: REVIEW
Let’s review the KNN algorithm using a shiny app.
Open the Rmd. Find Example 1.
Run the R chunk and ignore the syntax!!
- Click “Go!” one time only to collect a set of sample data.
Check out the KNN with K = 1.
- What does it mean to pick K = 1?
- Where are the jumps made?
- Can we write the estimated \(f(x)\) (red line) as \(\beta_0 + \beta_1 x + ....\)?
Now try the KNN with K = 25.
- What does it mean to pick K = 25?
- Is this more or less wiggly / flexible than when K = 1?
Set K = 100 where 100 is the number of data points. Is this what you expected?
Small Group Discussion: Recap Video
EXAMPLE 2: BIAS-VARIANCE TRADEOFF
What would happen if we had gotten a different sample of data?!?
- Bias
On average, across different datasets, how close are the estimates of \(f(x)\) to the observed \(y\) outcomes?
- We have high bias if our estimates are far from the observed \(y\) outcomes.
- We have low bias if our estimates are close to the observed \(y\) outcomes.
- Variance
How variable are the estimates of \(f(x)\) from dataset to dataset? Are the estimates stable or do they vary a lot?
- We have high variance if our estimates change a lot from dataset to dataset.
- We have low variance if our estimates don’t change much from dataset to dataset.
To explore the properties of overly flexible models, set K = 1 and click “Go!” several times to change the sample data. How would you describe how KNN behaves from dataset to dataset.
To explore the properties of overly rigid models, repeat part a for K = 100.
To explore the properties of more “balanced” models, repeat part a for K = 25.
Small Group Discussion: Recap Video
EXAMPLE 3: BIAS-VARIANCE REFLECTION
In general…
- Why is “high bias” bad?
- Why is “high variability” bad?
- What is meant by the bias-variance tradeoff?
Small Group Discussion: Recap Video
EXAMPLE 4: BIAS-VARIANCE TRADEOFF FOR PAST ALGORITHMS
- Considering LASSO:
- For which values of \(\lambda\) (small or large) will LASSO be the most biased?
- For which values of \(\lambda\) (small or large) will LASSO be the most variable?
- The bias-variance tradeoff also comes into play when comparing across algorithms, not just within algorithms. Consider LASSO vs least squares:
- Which will tend to be more biased?
- Which will tend to be more variable?
- When will LASSO beat least squares in the bias-variance tradeoff game?
Small Group Activity
Work as a group on exercises 1 - 12.
Consider W.A.I.T. Why Am/Aren’t I Talking?
- Actively work to give everyone a chance to contribute and share.
After Class
KNN & Bias Variance Tradeoff
- Finish the activity, check the solutions, watch the R Tutorial video, and reach out with questions.
- Continue to check in on Slack.
- If you search for me, you’ll find all of the info I’ve posted in our workspace.
Group Assignment
- If you haven’t already, open the Group Assignment 1 in Moodle.
- Read the directions.
- Start exploring the data and potential models on your own (spend ~ 2 hours getting a handle of the data)
- Make visualizations, fit models, evaluate models
- This is great practice / review of code & concepts.
Upcoming due dates
- TODAY: HW 3
- Thursday: Checkpoint 7 (this is the halfway mark on the 14 checkpoints :))
- Friday: HW 2 Revisions
- 2 weeks from today: Concept Quiz 1 on Units 1–3