Evaluating Classification Models
Where are we?
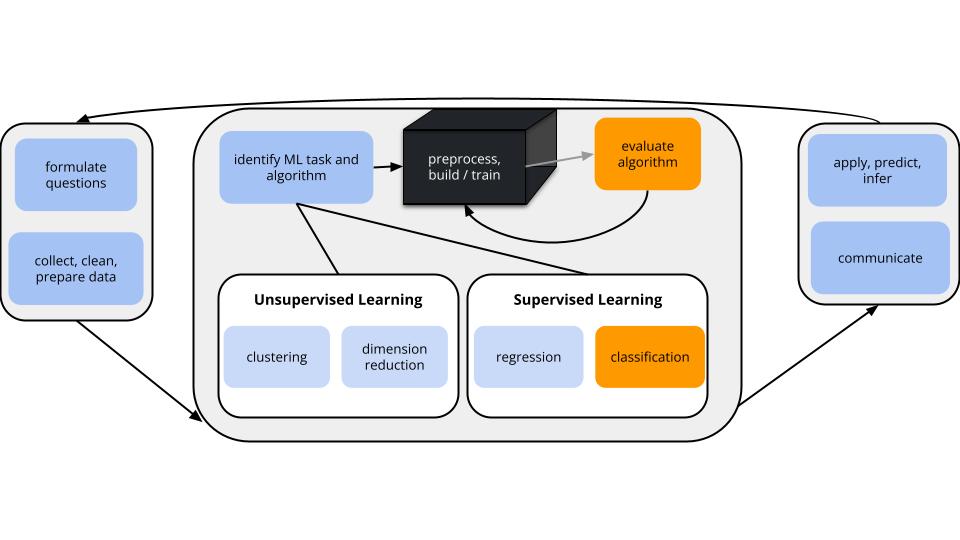
CONTEXT
world = supervised learning
We want to model some output variable \(y\) using a set of potential predictors \((x_1, x_2, ..., x_p)\).task = CLASSIFICATION
\(y\) is categorical and binary(parametric) algorithm
logistic regressionapplication = classification
- Use our algorithm to calculate the probability that y = 1.
- Turn these into binary classifications using a classification rule. For some probability threshold c:
- If the probability that y = 1 is at least c, classify y as 1.
- Otherwise, classify y as 0.
- WE get to pick c. This should be guided by context (what are the consequences of misclassification?) and the quality of the resulting classifications.
GOAL
Evaluate the quality of binary classifications of \(y\) (here resulting logistic regression model).
Example 1
Suppose we model RainTomorrow in Sydney using only the number of hours of bright Sunshine today.
Using a probability threshold of 0.5, this model produces the following classification rule:
- If
Sunshine< 3.125, predict rain. - Otherwise, predict no rain.
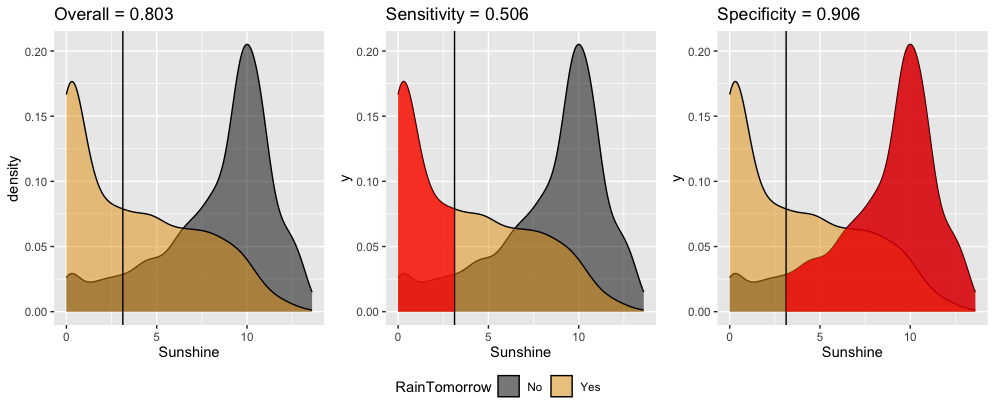
Interpret these in-sample estimates of the resulting classification quality.
- Overall accuracy = 0.803
- We correctly predict the rain outcome (yes or no) 80.3% of the time.
- We correctly predict “no rain” on 80.3% of non-rainy days.
- We correctly predict “rain” on 80.3% of rainy days.
- Sensitivity = 0.506
- We correctly predict the rain outcome (yes or no) 50.6% of the time.
- We correctly predict “no rain” on 50.6% of non-rainy days.
- We correctly predict “rain” on 50.6% of rainy days.
- Specificity = 0.906
- We correctly predict the rain outcome (yes or no) 90.6% of the time.
- We correctly predict “no rain” on 90.6% of non-rainy days.
- We correctly predict “rain” on 90.6% of rainy days.
Example 2
We can change up the probability threshold in our classification rule! The ROC curve for our logistic regression model of RainTomorrow by Sunshine plots the sensitivity (true positive rate) vs 1 - specificity (false positive rate) corresponding to “every” possible threshold:
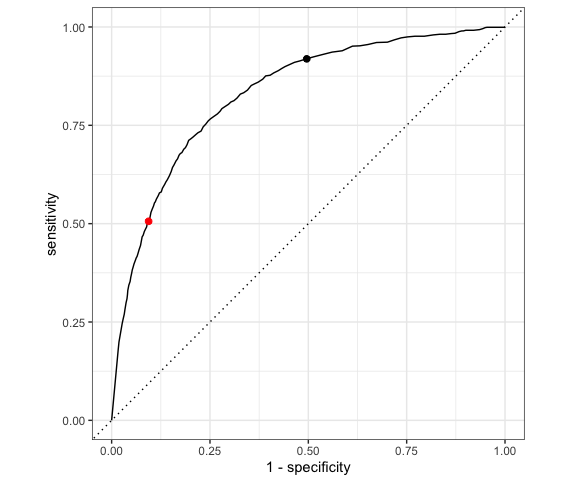
Which point represents the quality of our classification rule using a 0.5 probability threshold?
The other point corresponds to a different classification rule which uses a different threshold. Is that threshold smaller or bigger than 0.5?
Which classification rule do you prefer?
Example 3
The area under an ROC curve (AUC) estimates the probability that our algorithm is more likely to classify y = 1 (rain) as 1 (rain) than to classify y = 0 (no rain) as 1 (rain), hence distinguish between the 2 classes. AUC is helpful for evaluating and comparing the overall quality of classification models. Consider 3 different possible predictors (A, B, C) of rainy and non-rainy days:
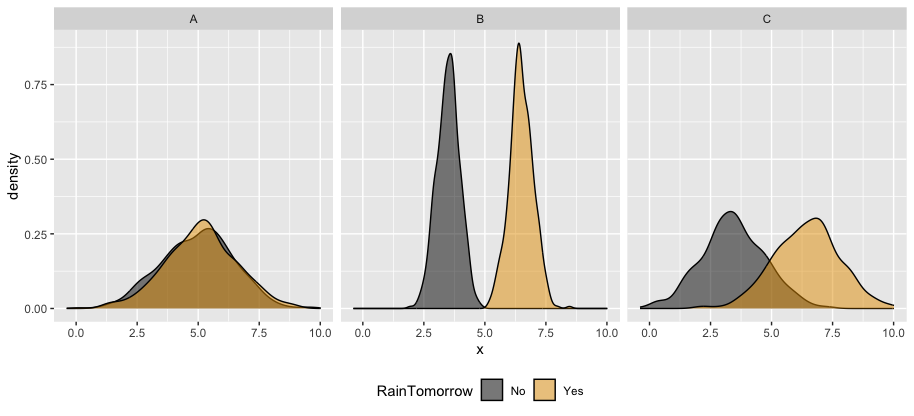
Which predictor is the “strongest” predictor of rain tomorrow?
The ROC curves corresponding to the models RainTomorrow ~ A, RainTomorrow ~ B, RainTomorrow ~ C are shown below.
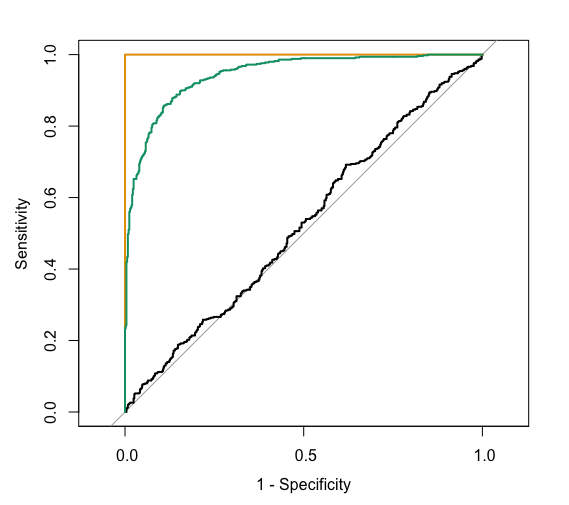
For each ROC curve, indicate the corresponding model and the approximate AUC. Do this in any order you want!
black ROC curve
RainTomorrow ~ ___- AUC is roughly ___
green ROC curve
RainTomorrow ~ ___- AUC is roughly ___.
orange ROC curve
RainTomorrow ~ ___- AUC is exactly ___.
After Class
Concept Quiz 1
- Revise Quiz 1 Part 1 (due Friday at 5pm)
- For any X, write a more correct answer and why the original was not quite right.
- My goal: Your understanding / learning
- You may talk with any current Stat 253 student, preceptor, or instructor.
Group Assignment
- Due tonight.
- Most important: your justification of your final model; show your understanding of concepts in your justification.
- If you are encountering errors, let me know.
- Computational intensity is a valid justification for or against models, but if you are getting errors, then you are missing something.
Upcoming due dates
- Today: Group Assignment 1
- Step 1: Submit brief report.
- Step 2: Submit test MAE.
- Friday: HW 5
- Please install 2 packages before Thursday’s class:
rpartandrpart.plot