Topic 1 Introductions
Learning Goals
- Identify the appropriate task (regression, classification, unsupervised) for a given research question.
- Develop foundation to be able to: Formulate research questions that align with regression, classification, or unsupervised learning tasks.
Small Group Discussion: Envisioning a Community of Learners
Directions:
- In small groups, please first introduce yourselves in whatever way you feel appropriate (e.g. name, pronouns, how you’re feeling at the moment, things you’re looking forward to, best part of winter break, why you are motivated to take this class).
- When everyone is ready, discuss the prompts below. One of you volunteer to record a few thoughts in this Google Doc. The instructor will summarize responses from all the sections to create a resource that everyone can use.
Prompts:
Collectivist education focuses on prioritizing the group first before the individual while individualist education focuses solely on the success of the individual. Considering your own experiences and backgrounds, discuss your values as they relate to collectivist and individualistic aspects of your own education.
It is important to create a set of agreements to guide our community in and out of class. Which of the following do you think are most important to keep in mind for our time together in this course and why? What might you add to our guiding principles?
- W.A.I.T. (Why Am I Talking/Why Aren’t I Talking)
- Be curious
- Extend and receive grace
- Understand impact vs. intention
- Breathe and lean into discomfort
- Embrace diversity of experience
What strategies have you found work well for you to succeed in learning both in and out of class that you want to continue this semester?
What are some things that have contributed to positive learning experiences in your courses that you would like to have in place for this course? What has contributed to negative experiences that you would like to prevent?
Notes: Overview
“Machine Learning” was coined back in 1959 by Arthur Samuel, an early contributor to AI.
From Kohavi & Provost (1998): Machine Learning is the exploration & application of algorithms that can learn from existing patterns and make predictions using data. (NOTE: humans are in charge of the exploration & application!)
In STAT 253 we will…
Pick up where STAT 155 left off, acquiring tools that can be used to learn from data in greater depth and a wider variety of settings. (STAT 155 is a foundational subset of ML!)
Explore universal ML concepts using tools and software common among statisticians (hence “statistical” machine learning).
Survey a breadth of modern ML tools and algorithms that fall into the workflow below. We’ll focus on concepts and applications over mathematical theory. Part of the cognitive load will be:
- keeping all the tools in place (what are they and when to use them)
- understanding the connections between the tools
- adapting (not memorizing) code to implement each tool
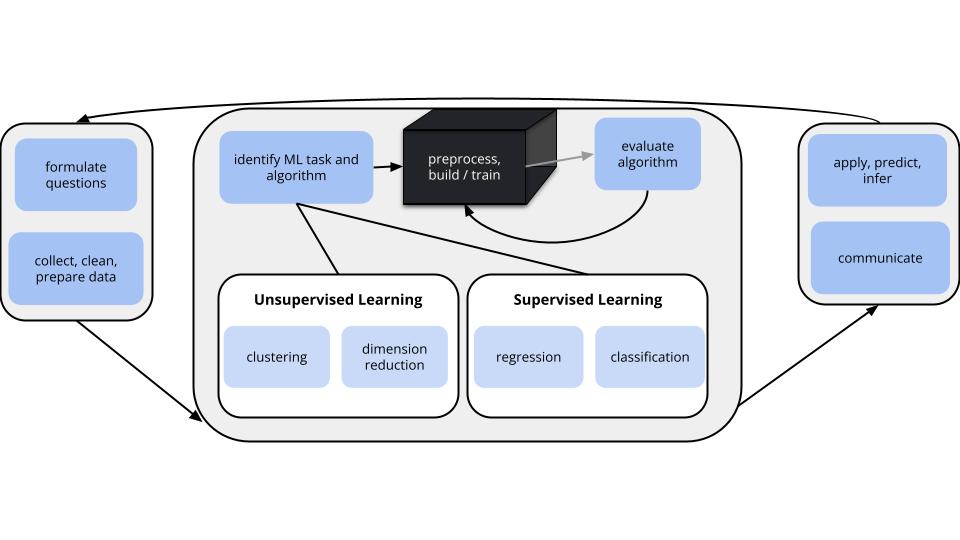
SUPERVISED LEARNING
We want to model the relationship between some output variable \(y\) and input variables \(x = (x_1, x_2,..., x_p)\):
\[\begin{split} y & = f(x) + \varepsilon \\ & = \text{(trend in the relationship) } + \text{ (residual deviation from the trend `epsilon`)} \\ \end{split}\]
Types of supervised learning tasks:
regression: \(y\) is quantitative
example:
\(y\) = body mass index
\(x\) = (number of live births, age, marital status, education, etc)classification: \(y\) is categorical
example:
\(y\) = whether a pair of crickets courted (yes, no) \(x\) = (species, pair of same species, CHC profile, etc)
UNSUPERVISED LEARNING
We have some input variables \(x = (x_1, x_2,..., x_p)\) but there’s no output variable \(y\). Thus the goal is to use \(x\) to understand and/or modify the structure of our data with respect to \(x\).
Types of unsupervised learning tasks:
- clustering
Identify and examine groups or clusters of data points that are similar with respect to their \(x_i\) values. example:- \(x\) = (body mass index at 2 weeks, 1 month, 2 months, 4 months, 6 months, etc)
- dimension reduction
Turn the original set of \(p\) input variables, which are potentially correlated, into a smaller set of \(k < p\) variables which still preserve the majority of information in the originals. example:- \(x\) = (cuticular hydrocarbon compounds concentrations based on gas chromatography analysis)
In-Class Activity - Exercises
I used a machine learning algorithm, one we’ll learn later this semester, to form groups based on your responses to the pre-course informational survey. BUT it didn’t provide any explanation of why these are the groups it picked. To that end, we need humans.
Get into your assigned group.
- Everybody introduce themselves.
- Try to figure out why the algorithm put you into a group together. (I don’t personally know the answer!)
- Discuss the following scenarios as a group, then check your answers.
Indicate whether each scenario below represents a regression, classification, or clustering task.
How is the number of people that rent bikes on a given day in Washington, D.C. (\(y\)) explained by the temperature (\(x_1\)) and whether or not it’s a weekend (\(x_2\))?
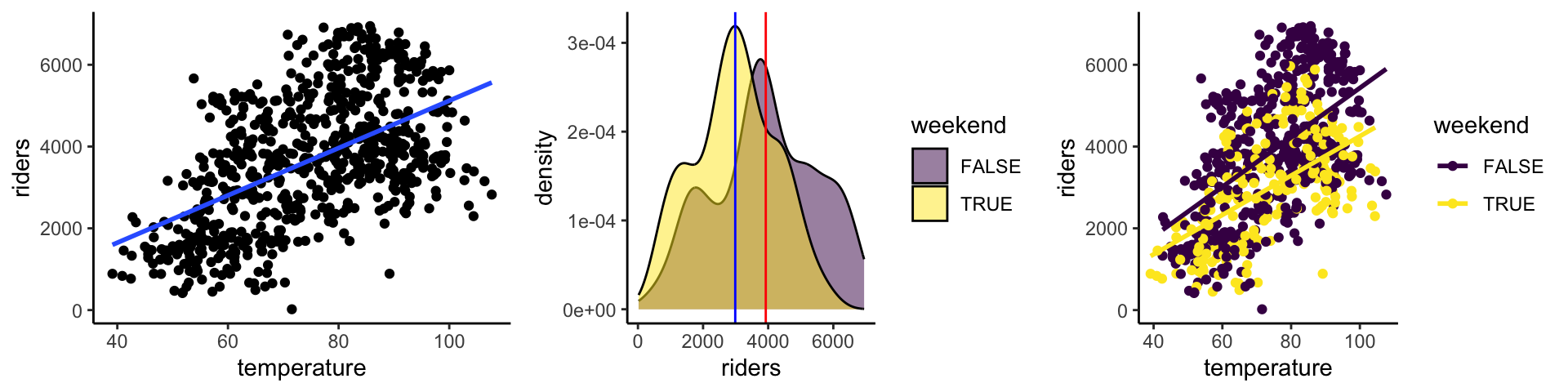
Solution
regression. there’s a quantitative output variable \(y\).- Given the observed bill length (\(x_1\)) and bill depth (\(x_2\)) on a set of penguins, how many different penguin species might there be?
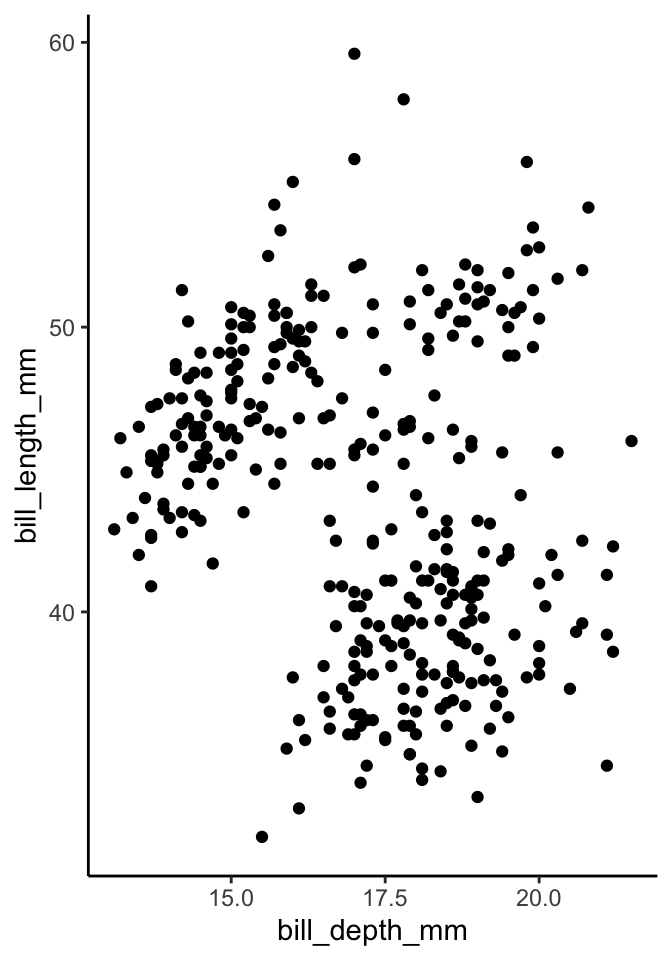
Solution
clustering. there’s no output variable \(y\).How can we determine whether somebody has a certain infection (\(y\)) based on two different blood sample measurements, Measure A (\(x_1\)) and Measure B (\(x_2\))?
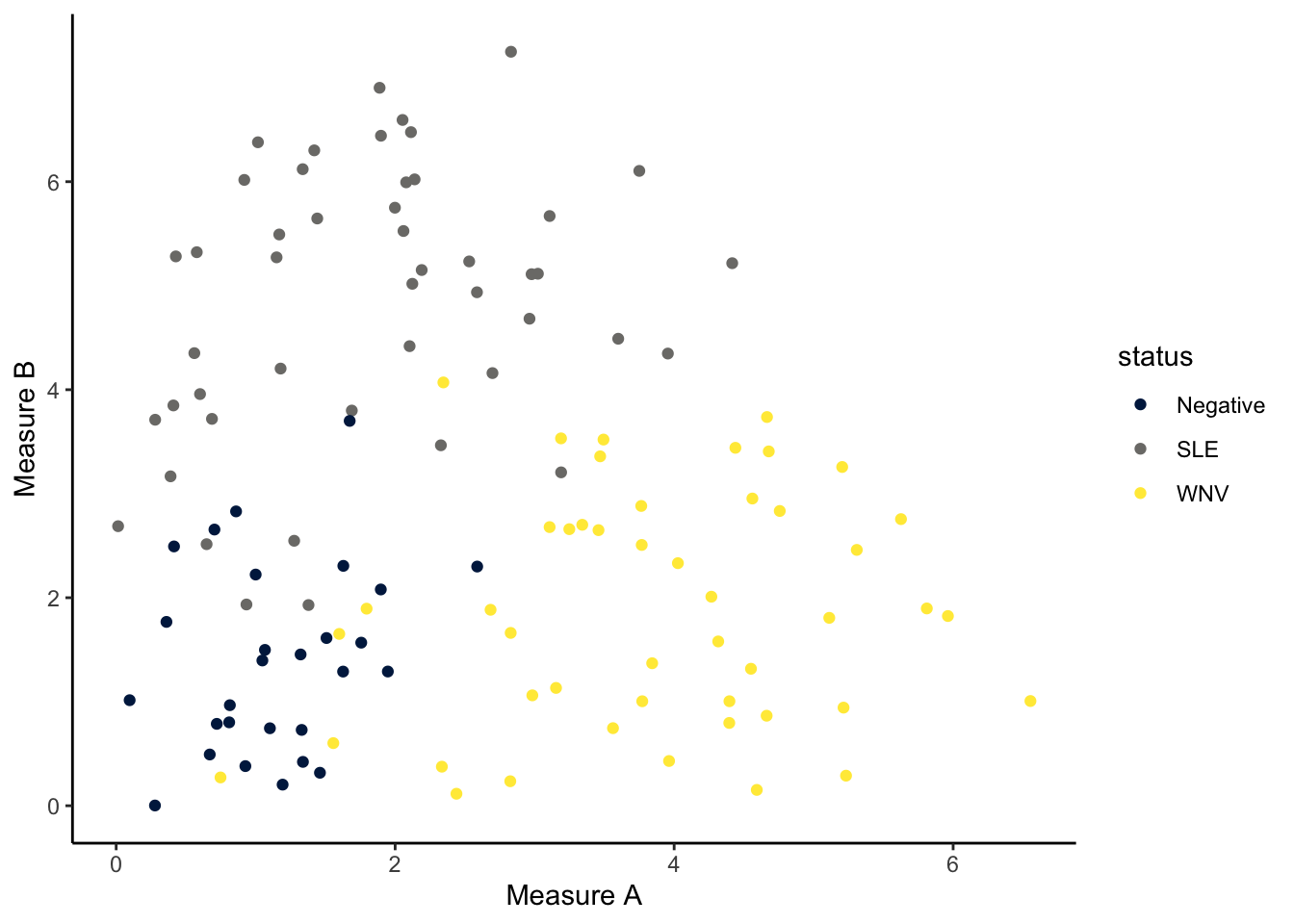
Solution
classification. there’s a categorical output variable \(y\).Machine learn about each other! Scenario A.
I collected some data on STAT 253 students (you!) and analyzed it using a machine learning algorithm. In your groups: (1) brainstorm what research question is being investigated; (2) determine whether this is a regression, classification, or clustering task; and (3) summarize what the output tells you about your classmates.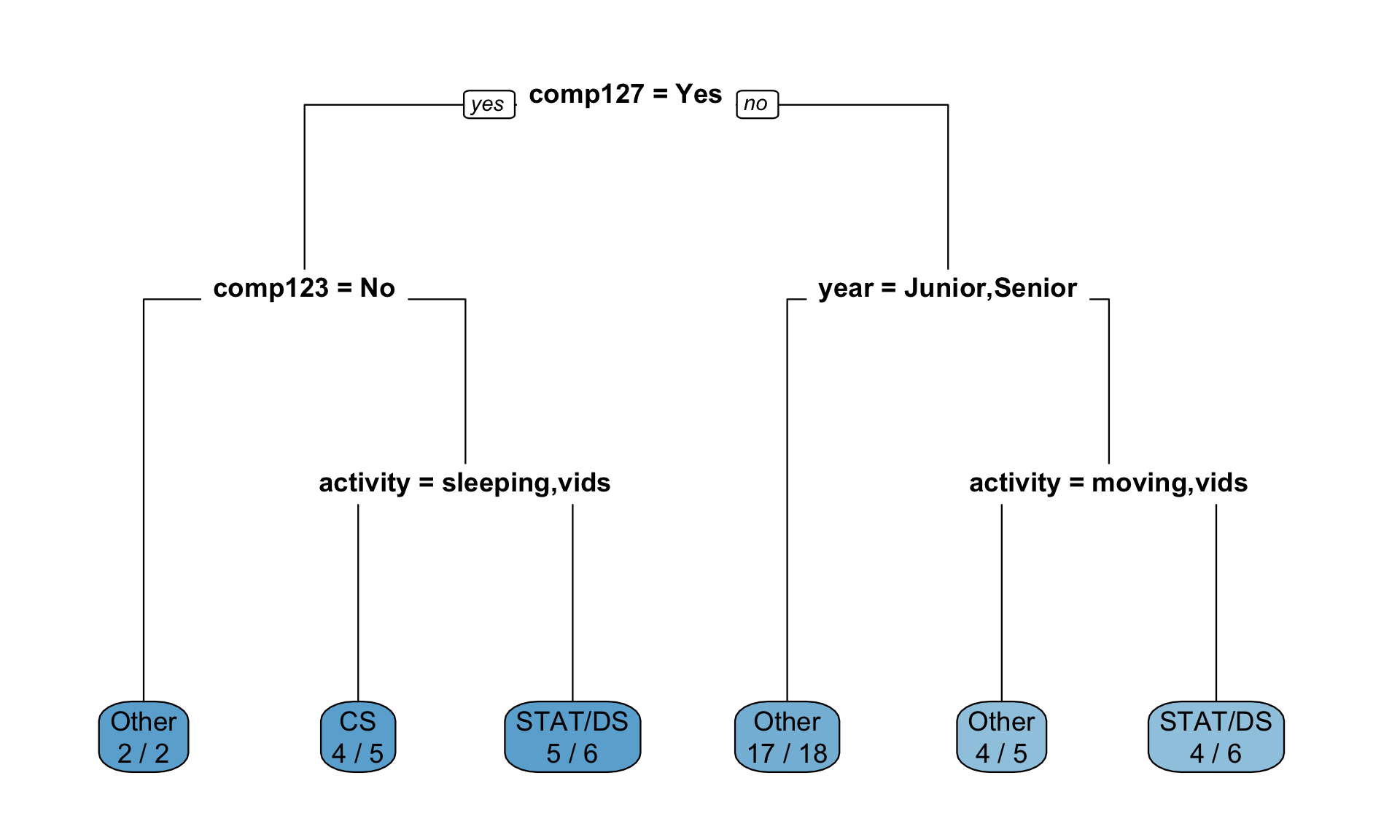
Solution
classification (\(y\) = major is categorical)- Machine learn about each other! Scenario B.
Same directions as for Scenario A:
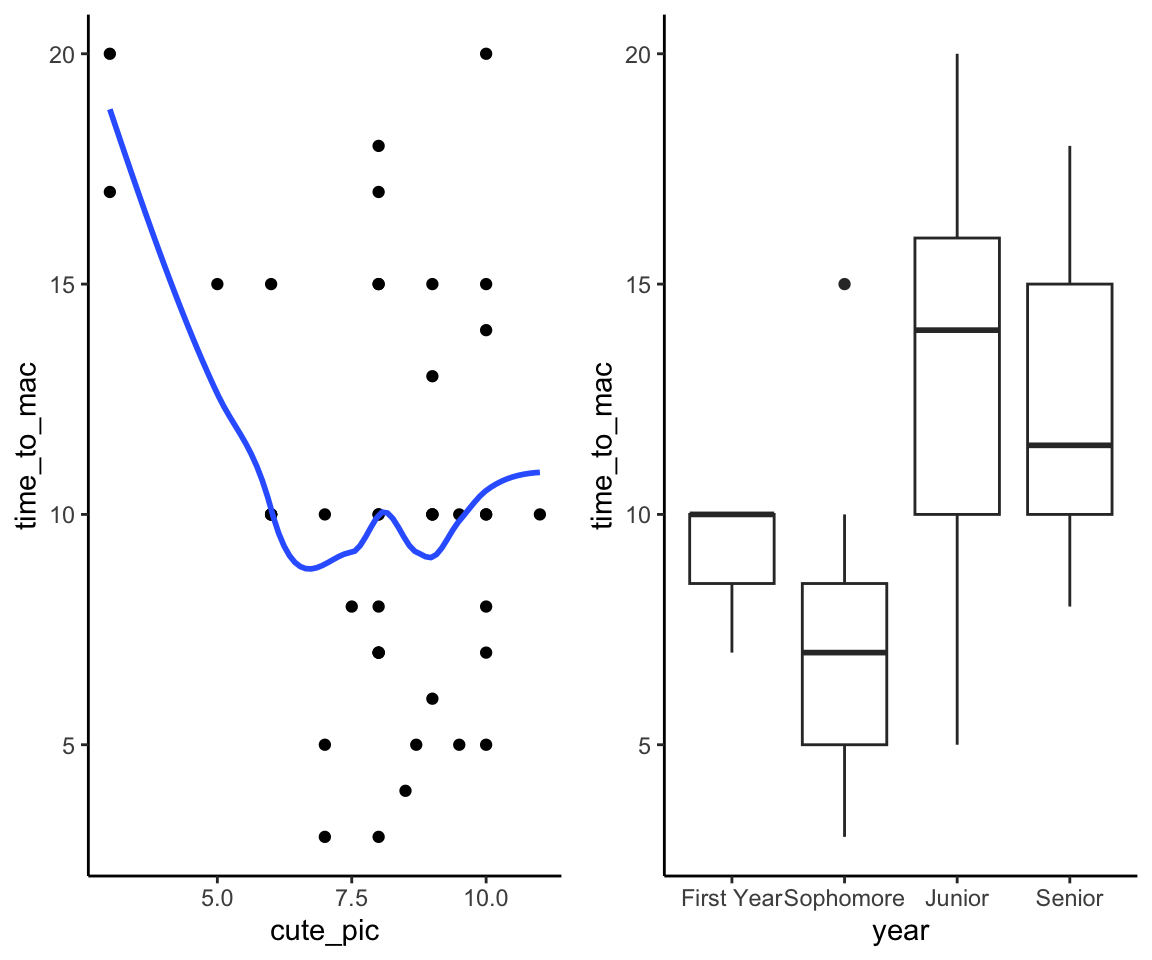
Solution
regression (\(y\) = time to mac is quantitative)- Machine learn about each other! Scenario C.
Same directions as for Scenario A:
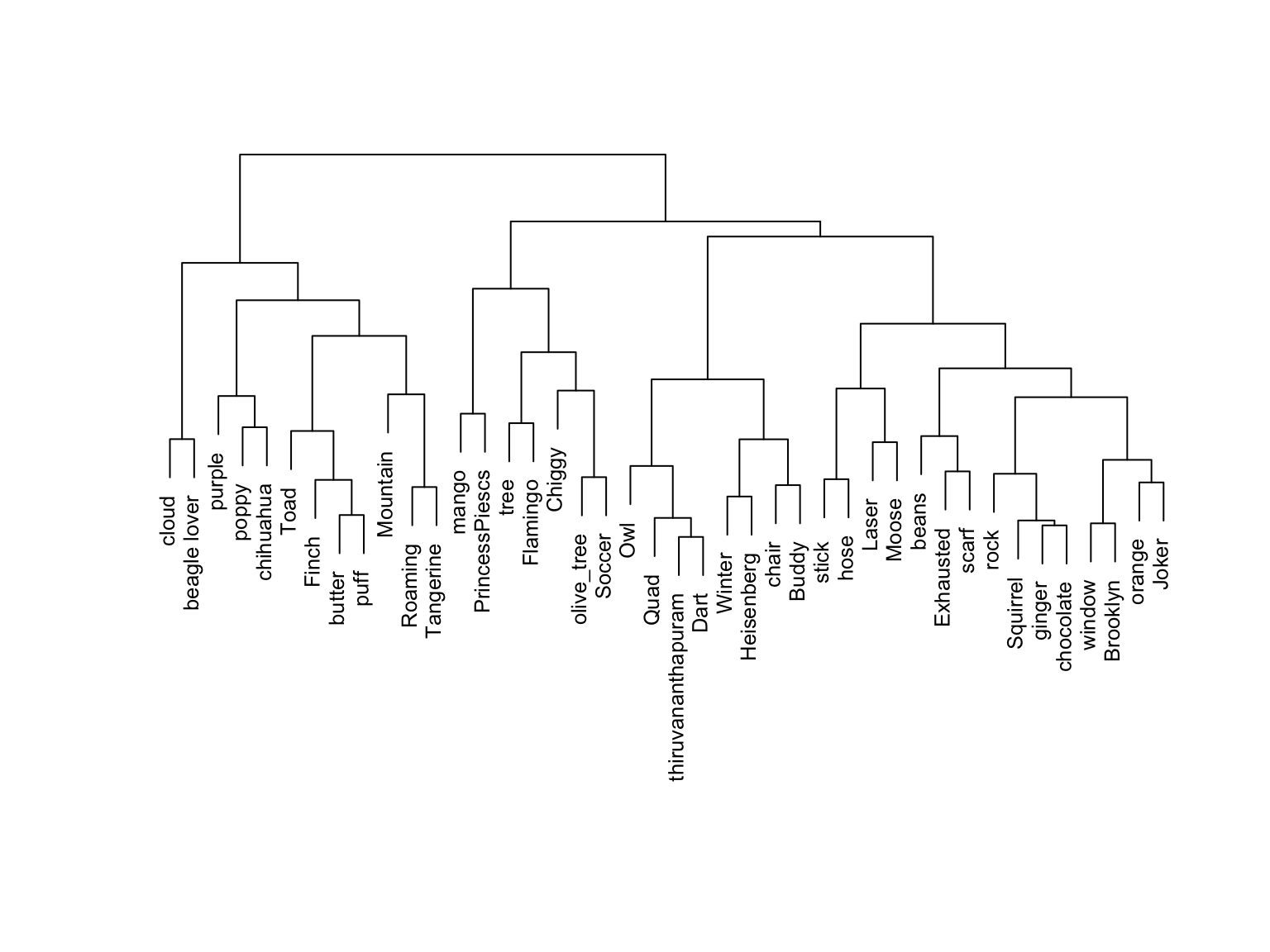
Solution
clustering (no outcome \(y\)).- Use Spotify users’ previous listening behavior to identify groups of similar users.
Solution
clustering
- Predict workers’ wages by their years of experience.
Solution
regression (\(y\) = wages)- Predict workers’ wages by their college major.
Solution
regression (\(y\) = wages)- Use a customer’s age to predict whether they’ve seen the Barbie movie.
Solution
classification (\(y\) = whether or not watched the film)- Look for similarities among genetic samples taken from a group of patients.