# Load packages & data
library(tidyverse)
data(penguins)13 Multiple linear regression: model building (part 1)
Settling In
- Sit where you’d like
- Introduce yourself
- Check in with each other.
- Help each other get ready to take notes!
- Open your notebook.
- Open the online manual to the “Course Schedule” and click on today’s activity. That brings you here!
- Download “13-mlr-model-building-1.qmd” and open it in RStudio. Read the “Organizing your files” directions at the top of the file!!
- Open your notebook.
Recap
NoteLearning goals
By the end of this lesson, you should be able to:
- Explain when variables are redundant or multicollinear.
- Relate redundancy and multicollinearity to coefficient estimates and R^2.
- Explain why adjusted R^2 is preferable to multiple R^2 when comparing models with different numbers of predictors.
NoteAdditional resources
Required:
Additional resources:
- Reading: Section 3.9.5 in the STAT 155 Notes
- Video: Redundancy and Multicollinearity
Model Building using Causal Diagram
Once you have a causal diagram with Y and a predictor of interest X_1, we’ll identify variables as one of the following based on the diagram structure.
Confounder Variable
A variable X_2 is a confounder if it is…
- causally associated with outcome Y
- (causally) associated with predictor of interest X_1
In other words, X_2 would be a common cause of Y and X_1.
The X_2 “confounds” or confuses the relationship of X_1 and Y.
Solution: Include confounders in our model.
Precision Variable
A variable X_2 is a precision variable if it is…
- causally associated with outcome Y
- not associated with predictor of interest X_1
Solution: Don’t have to include in model, but a good idea to include in model.
Effect Modifier
A variable X_2 is an effect modifier if it …
- effects the relationship between X_1 and Y
Mediator
A variable X_2 is a mediator if it …
- causally associated with outcome Y
- caused by predictor of interest X_1
Collider
A variable X_2 is a collider if it …
- caused by outcome Y
- caused by predictor of interest X_1
NoteConsiderations in model building
Thus far, you’ve largely been told which models to fit. But outside the classroom, this is a decision you have to make on your own! There are various issues to consider in this process:
- Model quality: is it correct? strong? fair?
- Research question: what are you hoping to answer?!
- Practicality:
- what resources (time, money, etc) are necessary to building and implementing your model?
- do you and others need to be able to interpret your model? or are you just looking for good predictions?
Warm-up
Example 1: Research questions
- Predictive research questions
- Goal: Build a model using our sample data that we can use to predict outcomes outside our sample.
- Approach: Use any available predictors that help us reach this goal!
- Interpretability: We don’t necessarily care about whether our model turns out to be complicated (within limits!).
- Context: “Machine learning” is often associated with predictive questions.
- Descriptive & inferential research questions
- Goal: Better understand and make inferences about specific relationships of interest (within and beyond our sample).
- Approach: Predictors are defined by the relationships of interest.
- Interpretability: We need to be able to interpret the model!
- Causal research questions
- Goal: A type of inferential research question that specifically seeks to establish causality.
- Approach: Include the predictor(s) of interest AND all potential confounders.
- Interpretability: We need to be able to interpret the model!
For each research question / goal below (from Prof Johnson’s stint at the CDC’s Division of Vector-Borne Diseases), identify what type it is.
Each of these questions were answered using statistical models!
- Does a new mosquito repellent effectively prevent mosquito bites?
- Use blood samples and other info sent into the lab to determine if somebody contracted the West Nile Virus.
- How much West Nile Virus do mosquitos carry in their saliva and does this differ by species and age?
Exercises
In model building, we might feel tempted to throw more and more things into our model. In these exercises, we’ll use the penguins data to explore some nuances and limitations of this approach:
To get started, the flipper_len variable currently measures flipper length in mm. Let’s create and save a new variable named flipper_len_cm which measures flipper length in cm. NOTE: There are 10mm in a cm.
penguins <- penguins %>%
mutate(flipper_len_cm = flipper_len / 10)Run the code chunk below to build a bunch of models that you’ll be exploring in the exercises:
penguin_model_1 <- lm(bill_len ~ flipper_len, penguins)
penguin_model_2 <- lm(bill_len ~ flipper_len_cm, penguins)
penguin_model_3 <- lm(bill_len ~ flipper_len + flipper_len_cm, penguins)
penguin_model_4 <- lm(bill_len ~ body_mass, penguins)
penguin_model_5 <- lm(bill_len ~ flipper_len + body_mass, penguins)Exercise 1: Modeling bill length by flipper length
What can a penguin’s flipper (arm) length tell us about their bill length? To answer this question, we’ll consider 3 of our models:
| model | predictors |
|---|---|
penguin_model_1 |
flipper_len |
penguin_model_2 |
flipper_len_cm |
penguin_model_3 |
flipper_len + flipper_len_cm |
Plots of the first two models are below:
ggplot(penguins, aes(y = bill_len, x = flipper_len)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE)
ggplot(penguins, aes(y = bill_len, x = flipper_len_cm)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE)Before examining the model summaries, check your intuition. Do you think the
penguin_model_2R-squared will be less than, equal to, or more than that ofpenguin_model_1? Similarly, how do you think thepenguin_model_3R-squared will compare to that ofpenguin_model_1?Check your intuition: Examine the R-squared values for the three penguin models and summarize how these compare.
summary(penguin_model_1)$r.squared
summary(penguin_model_2)$r.squared
summary(penguin_model_3)$r.squared- Explain why your observation in part b makes sense. Support your reasoning with a plot of just the 2 predictors:
flipper_lenvsflipper_len_cm.
In
summary(penguin_model_3), theflipper_len_cmcoefficient isNA. Explain why this makes sense. THINK: Theflipper_len_cmcoefficient would tell us the change in the expected bill length per centimeter change in flipper length, while holding flipper length in millimeters constantBONUS: For those of you that have taken MATH 236 (Linear Alebra), the NA is the result of matrices that are not of full rank!
Exercise 2: Incorporating body_mass
Let’s now consider models of bill_len using flipper_len and/or body_mass:
| model | predictors | R-squared |
|---|---|---|
penguin_model_1 |
flipper_len |
0.431 |
penguin_model_4 |
body_mass |
0.354 |
penguin_model_5 |
flipper_len + body_mass |
TBD (do NOT calculate) |
Which is the better predictor of
bill_len:flipper_lenorbody_mass? Provide some numerical evidence.penguin_model_5incorporates bothflipper_lenandbody_massas predictors. Before examining a model summary, ask your gut: Will thepenguin_model_5R-squared be close to 0.354, close to 0.431, or greater than 0.6?Check your intuition. Report the
penguin_model_5R-squared and summarize how this compares to that ofpenguin_model_1andpenguin_model_4.Explain why your observation in part c makes sense. Support your reasoning with a plot of the 2 predictors:
flipper_lenvsbody_mass.
Exercise 3: Redundancy and Multicollinearity
The exercises above illustrate special phenomena in multivariate modeling:
- two predictors are redundant if they contain the same exact information
- two predictors are multicollinear if they are strongly associated (they contain very similar information) but are not completely redundant.
Recall that we examined 5 models:
| model | predictors |
|---|---|
penguin_model_1 |
flipper_len |
penguin_model_2 |
flipper_len_cm |
penguin_model_3 |
flipper_len + flipper_len_cm |
penguin_model_4 |
body_mass |
penguin_model_5 |
flipper_len + body_mass |
- Which model had redundant predictors and which predictors were these?
- Which model had multicollinear predictors and which predictors were these?
- In general, what happens to the R-squared value if we add a redundant predictor to a model: will it decrease, stay the same, increase by a small amount, or increase by a significant amount?
- Similarly, what happens to the R-squared value if we add a multicollinear predictor to a model: will it decrease, stay the same, increase by a small amount, or increase by a significant amount?
Exercise 4: Considerations for strong models
Let’s dive deeper into important considerations when building a strong model. We’ll use a subset of the penguins data for exploring these ideas.
# For illustration purposes only, take a sample of 10 penguins.
# We'll discuss this code later in the course!
set.seed(155)
penguins_small <- sample_n(penguins, size = 10) %>%
mutate(flipper_len = jitter(flipper_len))Check out the relationship of bill_len with flipper_len for this sample:
penguins_small %>%
ggplot(aes(y = bill_len, x = flipper_len)) +
geom_point()Consider 3 models of bill length. Letting Y be bill_len and X be flipper_len:
- 1 predictor: E[Y | X] = \beta_0 + \beta_1 X
- 2 predictors: E[Y | X] = \beta_0 + \beta_1 X + \beta_2 X^2
- 9 predictors: E[Y | X] = \beta_0 + \beta_1 X + \beta_2 X^2 + \beta_3 X^3 + \beta_4 X^4 + \beta_5 X^5 + \beta_6 X^6 + \beta_7 X^7 + \beta_8 X^8 + \beta_9 X^9
These models are estimated below:
# A model with 1 predictor (flipper_len)
poly_mod_1 <- lm(bill_len ~ flipper_len, penguins_small)
# A model with 2 predictors (flipper_len and flipper_len^2)
poly_mod_2 <- lm(bill_len ~ poly(flipper_len, 2), penguins_small)
# A model with 9 predictors (flipper_len, flipper_len^2, ... on up to flipper_len^9)
poly_mod_9 <- lm(bill_len ~ poly(flipper_len, 9), penguins_small)- Before doing any analysis, which of the three models do you think will be best?
- Calculate the R-squared values of these 3 models. Which model do you think is best?
summary(poly_mod_1)$r.squared
summary(poly_mod_2)$r.squared
summary(poly_mod_9)$r.squared- Check out plots depicting the relationship estimated by these 3 models. Which model do you think is best?
# A plot of model 1
ggplot(penguins_small, aes(y = bill_len, x = flipper_len)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE)# A plot of model 2
ggplot(penguins_small, aes(y = bill_len, x = flipper_len)) +
geom_point() +
geom_smooth(method = "lm", formula = y ~ poly(x, 2), se = FALSE)# A plot of model 9
ggplot(penguins_small, aes(y = bill_len, x = flipper_len)) +
geom_point() +
geom_smooth(method = "lm", formula = y ~ poly(x, 9), se = FALSE)Exercise 5: Reflecting on these investigations
- List 3 of your favorite foods. Now imagine making a dish that combines all of these foods. Do you think it would taste good?
- Too many good things doesn’t make necessarily make a better thing. Model 9 demonstrates that it’s always possible to get a perfect R-squared of 1, but there are drawbacks to putting more and more predictors into our model. Answer the following about model 9:
- How easy would it be to interpret this model?
- Would you say that this model captures the general trend of the relationship between
bill_lenandflipper_len? - How well do you think this model would generalize to penguins that were not included in the
penguins_smallsample? For example, would you expect these new penguins to fall on the wiggly model 9 curve?
Exercise 6: Overfitting
- We say that
poly_mod_9is overfit to the 10 penguins in thepenguins_smalldataset. To understand this term, applypoly_mod_9to the 344 penguins in the original dataset. In your own words, describe what “overfit” means.
penguins %>%
ggplot(aes(y = bill_len, x = flipper_len)) +
geom_point() +
geom_smooth(method = "lm", formula = y ~ poly(x, 9), se = FALSE, data = penguins_small) +
geom_point(data = penguins_small, color = "red", size = 3)- Check out the following xkcd comic. Which plot pokes fun at overfitting?
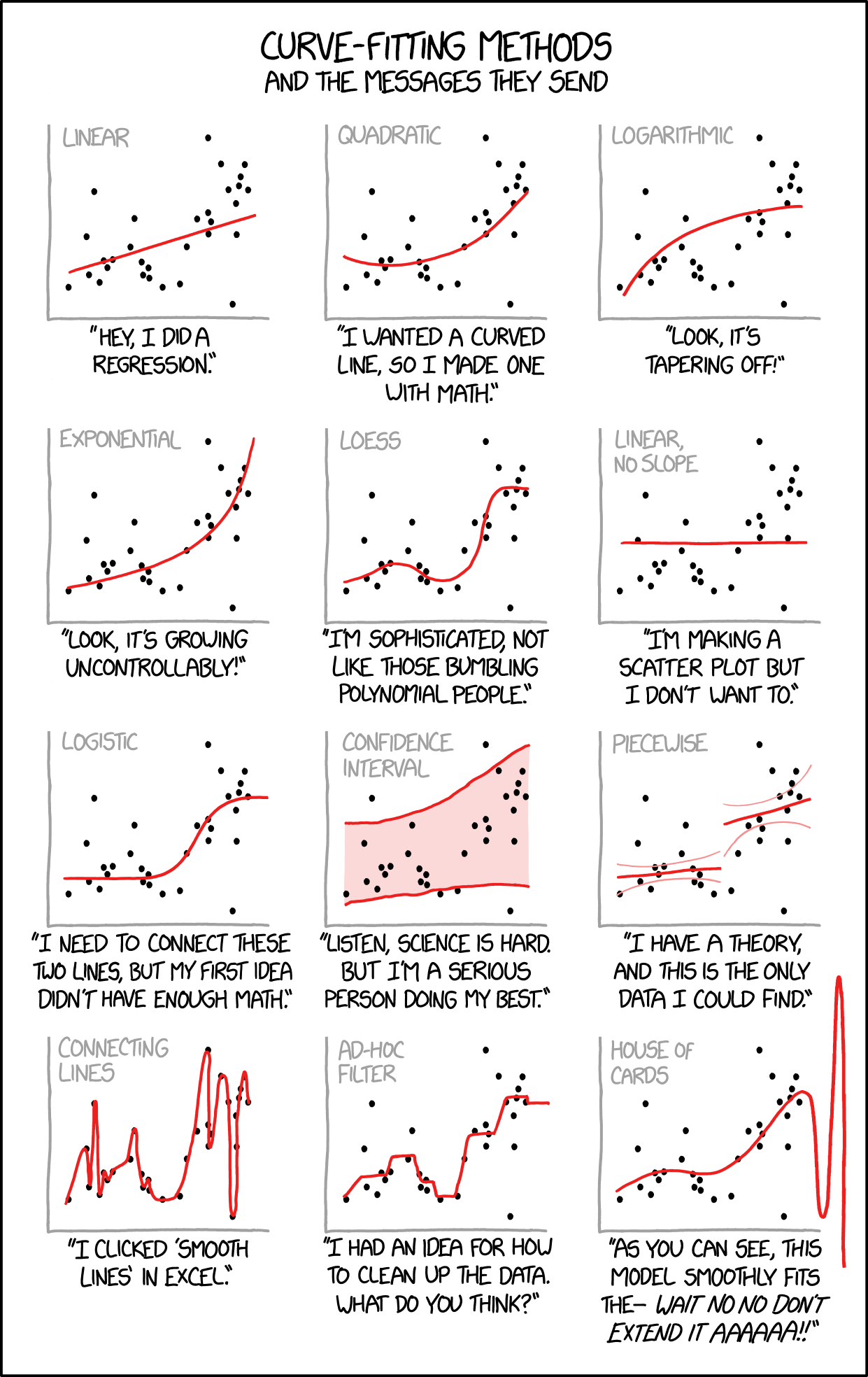
- Check out some other goodies:


Exercise 7: Questioning R-squared
Zooming out, explain some limitations of relying on R-squared to measure the strength / usefulness of a model.
Exercise 8: Adjusted R-squared
We’ve observed that, unless a predictor is redundant with another, R-squared will increase. Even if that predictor is strongly multicollinear with another. Even if that predictor isn’t a good predictor! Thus if we only look at R-squared we might get overly greedy. We can check our greedy impulses a few ways. We take a more in depth approach in STAT 253, but one quick alternative is reported right in our model summary() tables. Adjusted R-squared includes a penalty for incorporating more and more predictors. Mathematically (where n is the sample size and p is the number of non-intercept coefficients):
\text{Adjusted } R^2 = 1 - (1 - R^2) \left( \frac{n-1}{n-p-1} \right)
As we add more predictors into a model, R-squared increases, BUT the number of non-intercept coefficients p also increases. Thus unlike R-squared, Adjusted R-squared can decrease if the information that a predictor contributes to a model (reflected by R-squared) isn’t enough to offset the complexity it adds to that model (reflected by p). Consider two models:
example_mod_1 <- lm(bill_len ~ species, penguins)
example_mod_2 <- lm(bill_len ~ species + island, penguins)- Check out the summaries for the 2 example models and summarize your observations in this table:
| Model | R-squared | Adj R-squared |
|---|---|---|
| bill_len ~ species | ??? | ??? |
| bill_len ~ species + island | ??? | ??? |
- In general, how does a model’s Adjusted R-squared compare to the R-squared? Is it greater, less than, or equal to the R-squared?
- How did the R-squared change from example model 1 to model 2? How did the Adjusted R-squared change?
- Explain what it is about
islandthat resulted in a decreased Adjusted R-squared. Note: it’s not necessarily the case thatislandis a bad predictor on its own! - Pulling this all together, which is the “better” of these 2 models?
Reflection
Today we looked at some cautions surrounding indiscriminately adding variables to a model. Summarize key takeaways.
Response: Put your response here.
Wrap Up
This Friday:
- No Class
- Complete project group preference form (link on Moodle)
- Attend 2 MSCS Capstone Talks
- See MSCS Capstone Schedule in Moodle & on Slack!
- Complete Reflections about talks in Capstone Reflection Moodle assignment
Next Monday, 3/9:
- CP 10, PS 4 Due
Solutions
Exercises
Exercise 1: Modeling bill length by flipper length
Solution
| model | predictors |
|---|---|
penguin_model_1 |
flipper_len |
penguin_model_2 |
flipper_len_cm |
penguin_model_3 |
flipper_len + flipper_len_cm |
Plots of the first two models are below:
ggplot(penguins, aes(y = bill_len, x = flipper_len)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE)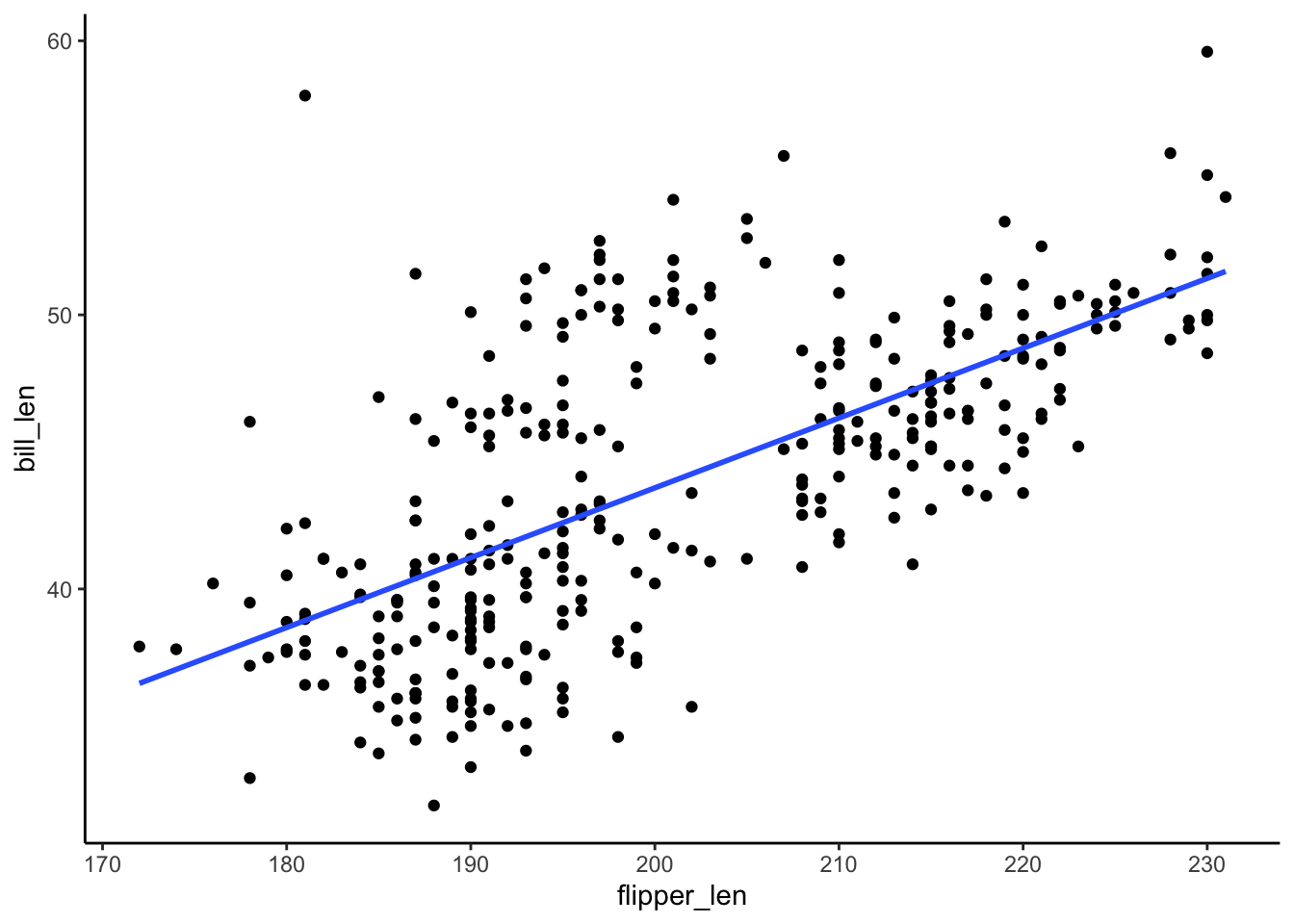
ggplot(penguins, aes(y = bill_len, x = flipper_len_cm)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE)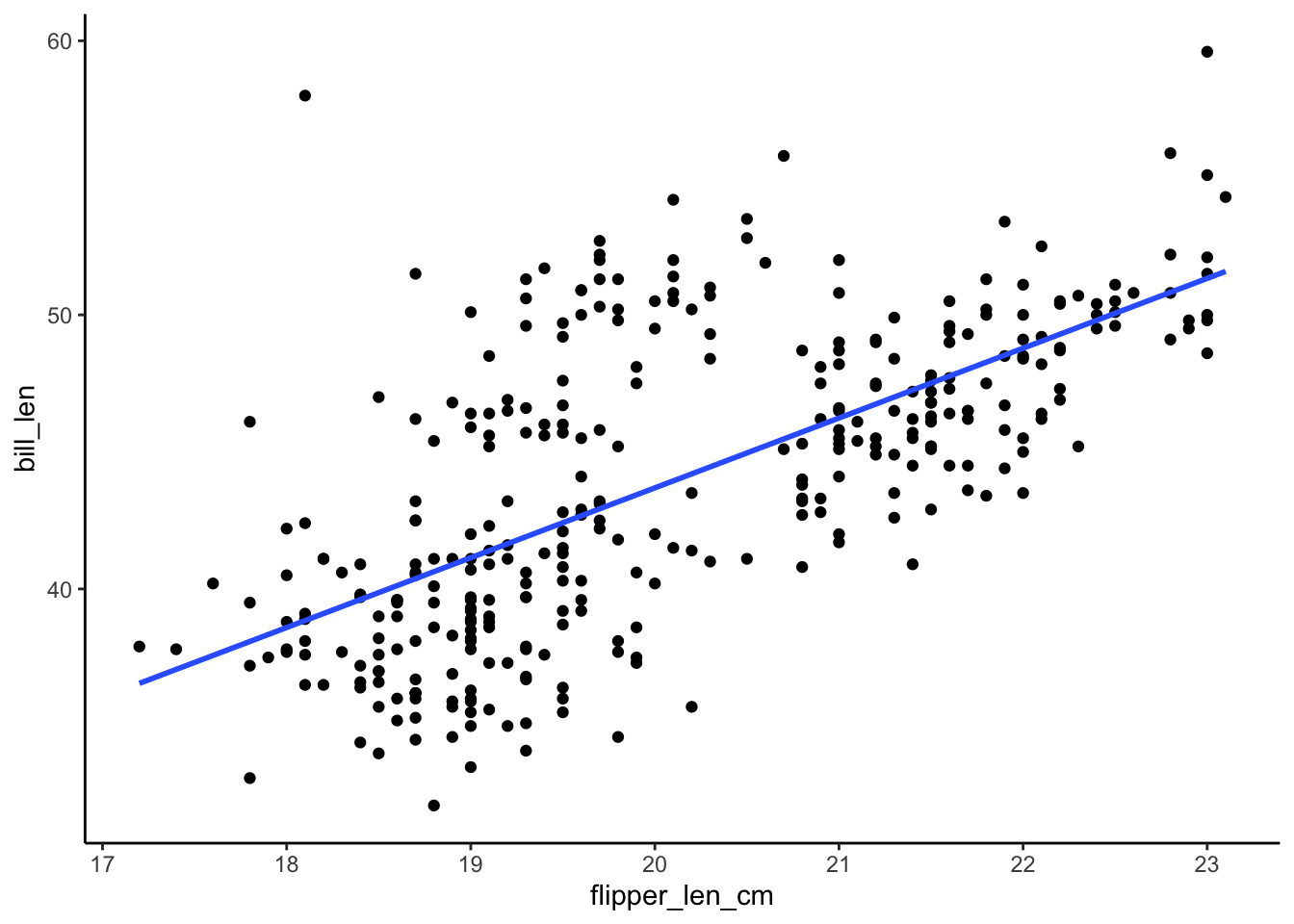
Your intuition–answers will vary
The R-squared values are all the same!
summary(penguin_model_1)$r.squared[1] 0.430574summary(penguin_model_2)$r.squared[1] 0.430574summary(penguin_model_3)$r.squared[1] 0.430574- The two variables are perfectly linearly correlated—they contain exactly the same information!
ggplot(penguins, aes(x = flipper_len, y = flipper_len_cm)) +
geom_point()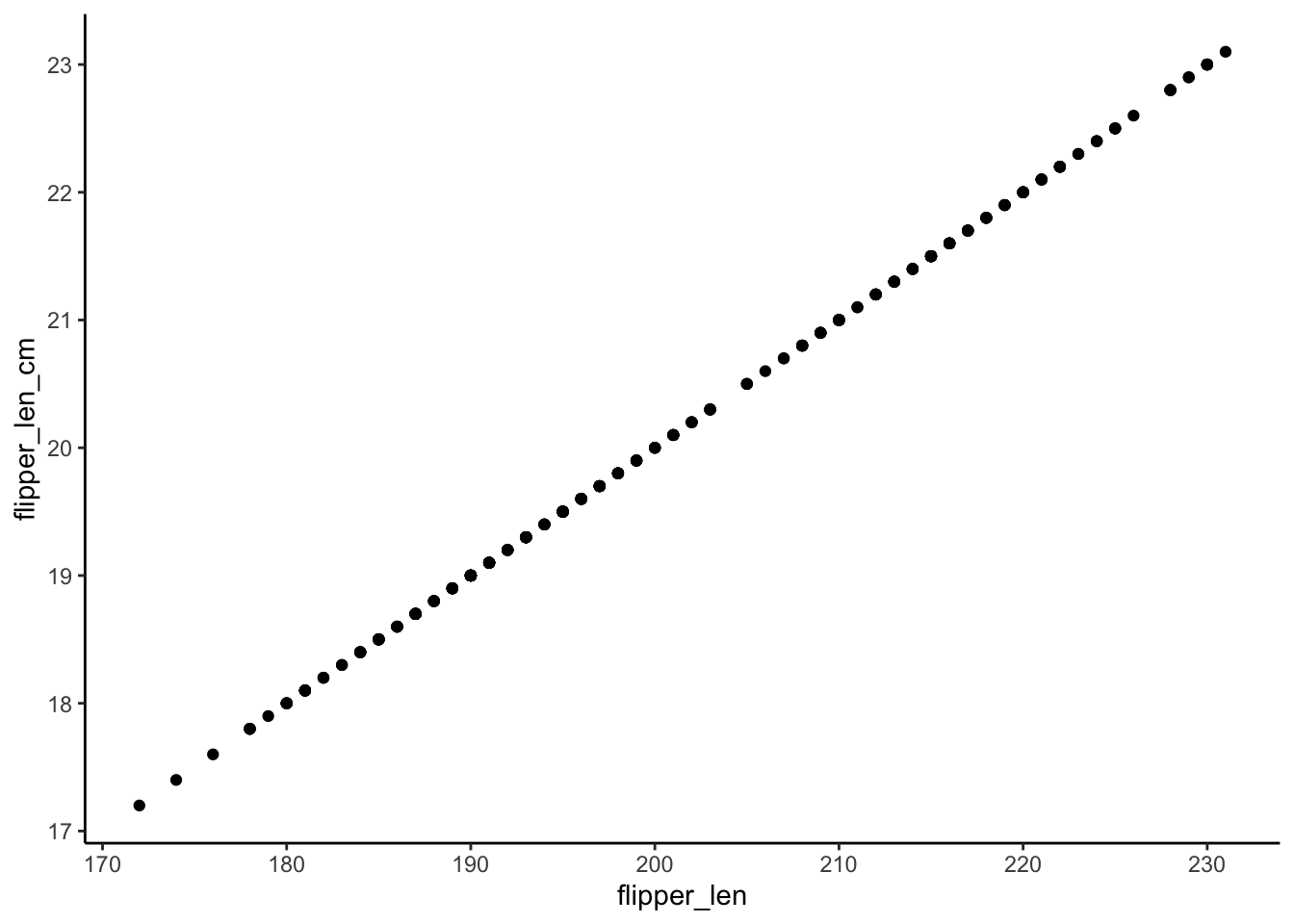
- An
NAmeans that the coefficient couldn’t be estimated. Inpenguin_model_3, the interpretation of theflipper_len_cmcoefficient is the average change in bill length per centimeter change in flipper length, while holding flipper length in millimeters constant…this is impossible! We can’t hold flipper length in millimeters fixed while varying flipper length in centimeters—if one changes the other must. (In linear algebra terms, the matrix underlying our data is not of full rank.)
Exercise 2: Incorporating body_mass
Solution
In this exercise you’ll consider 3 models of bill_len:
| model | predictors |
|---|---|
penguin_model_1 |
flipper_len |
penguin_model_4 |
body_mass |
penguin_model_5 |
flipper_len + body_mass |
flipper_lenis a better predictor thanbody_massbecausepenguin_model_1has an R-squared value of 0.4306 vs 0.3542 forpenguin_model_4.Intuition check–answers will vary
R-squared is for
penguin_model_5which is very slightly higher than that ofpenguin_model_1andpenguin_model_4.
summary(penguin_model_5)$r.squared[1] 0.4328544d.flipper_len and body_mass are positively correlated and thus contain related information, but not completely redundant information. There’s some information in flipper length in explaining bill length that isn’t captured by body mass, and vice-versa.
ggplot(penguins, aes(x = flipper_len, y = body_mass)) +
geom_point()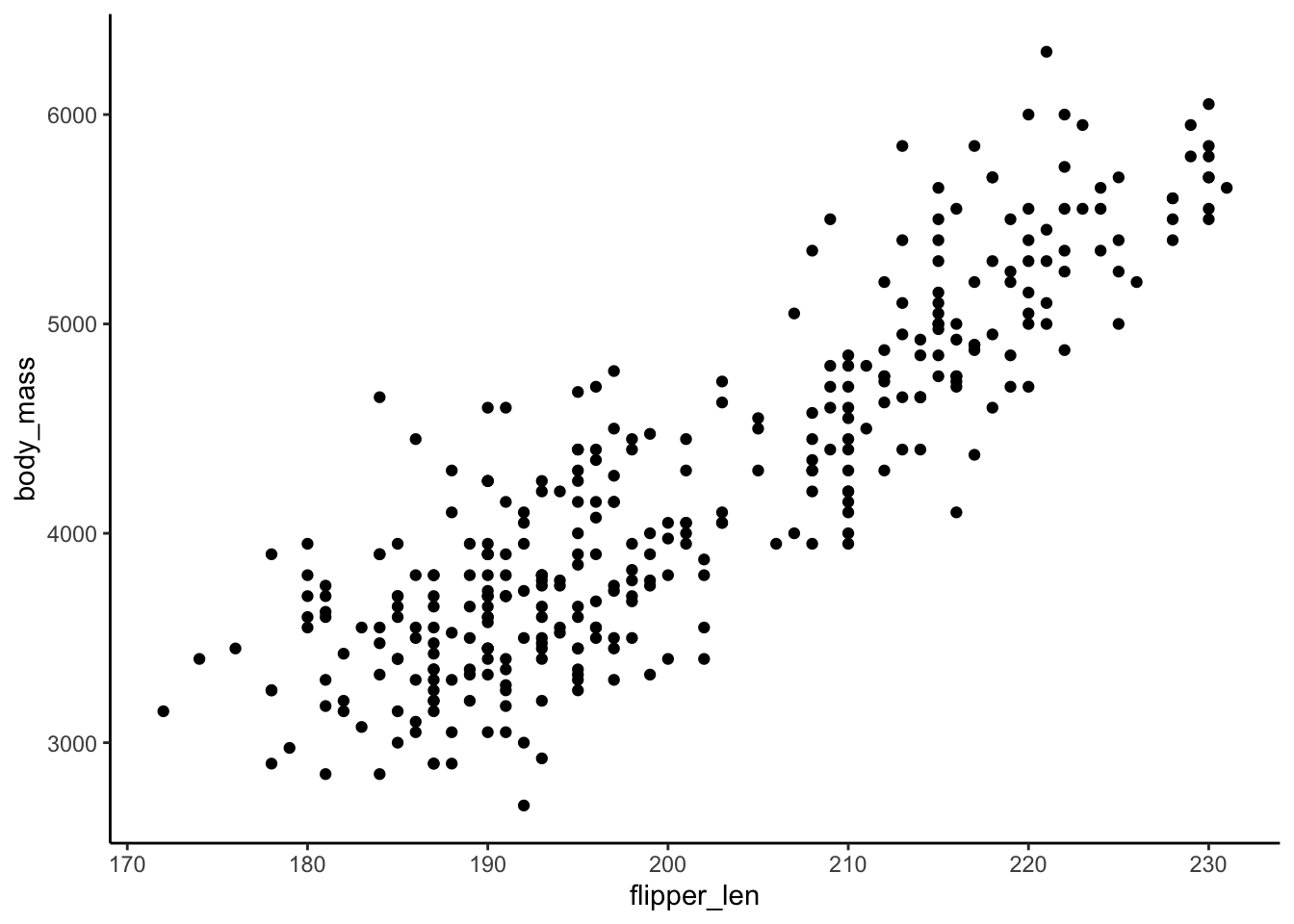
Exercise 3: Redundancy and Multicollinearity
Solution
| model | predictors |
|---|---|
penguin_model_1 |
flipper_len |
penguin_model_2 |
flipper_len_cm |
penguin_model_3 |
flipper_len + flipper_len_cm |
penguin_model_4 |
body_mass |
penguin_model_5 |
flipper_len + body_mass |
penguin_model_3had redundant predictors:flipper_lenandflipper_len_cmpenguin_model_5had multicollinear predictors:flipper_lenandbody_masswere related but not redundant- R-squared will stay the same if we add a redundant predictor to a model.
- R-squared will increase by a small amount if we add a multicollinear predictor to a model.
Exercise 4: Considerations for strong models
Solution
# For illustration purposes only, take a sample of 10 penguins.
# We'll discuss this code later in the course!
set.seed(155)
penguins_small <- sample_n(penguins, size = 10) %>%
mutate(flipper_len = jitter(flipper_len))
penguins_small %>%
ggplot(aes(y = bill_len, x = flipper_len)) +
geom_point()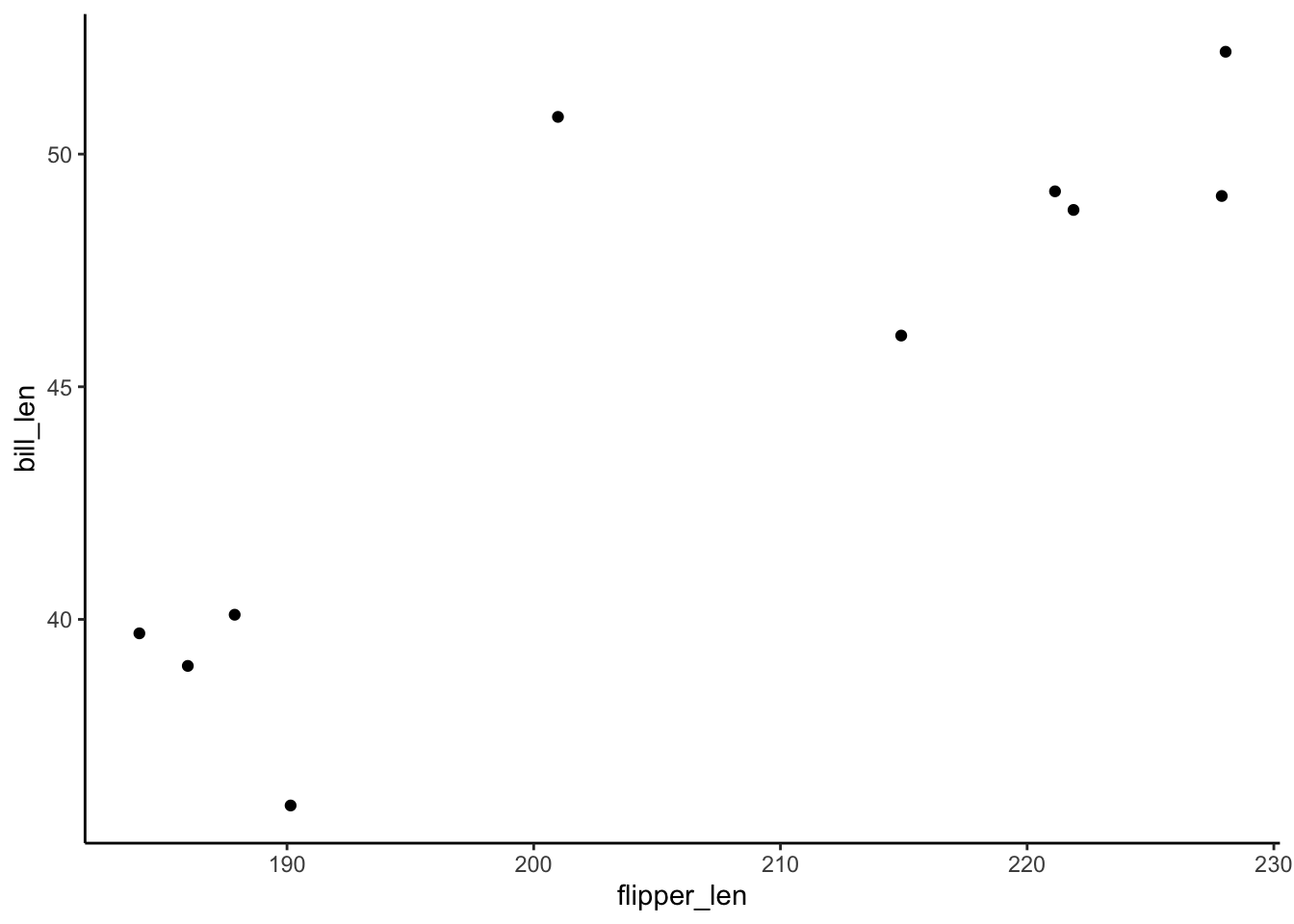
# A model with 1 predictor (flipper_len)
poly_mod_1 <- lm(bill_len ~ flipper_len, penguins_small)
# A model with 2 predictors (flipper_len and flipper_len^2)
poly_mod_2 <- lm(bill_len ~ poly(flipper_len, 2), penguins_small)
# A model with 9 predictors (flipper_len, flipper_len^2, ... on up to flipper_len^9)
poly_mod_9 <- lm(bill_len ~ poly(flipper_len, 9), penguins_small)- A gut check! Answers will vary
- Based on R-squared: recall that R-squared is interpreted as the proportion of variation in the outcome that our model explains. It would seem that higher is better, so
poly_mod_9might seem to be the best. BUT we’ll see where this reasoning is flawed soon!
summary(poly_mod_1)$r.squared[1] 0.7341412summary(poly_mod_2)$r.squared[1] 0.7630516summary(poly_mod_9)$r.squared[1] 1- Based on the plots: Model 1! Definitely not Model 9
# A plot of model 1
ggplot(penguins_small, aes(y = bill_len, x = flipper_len)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE)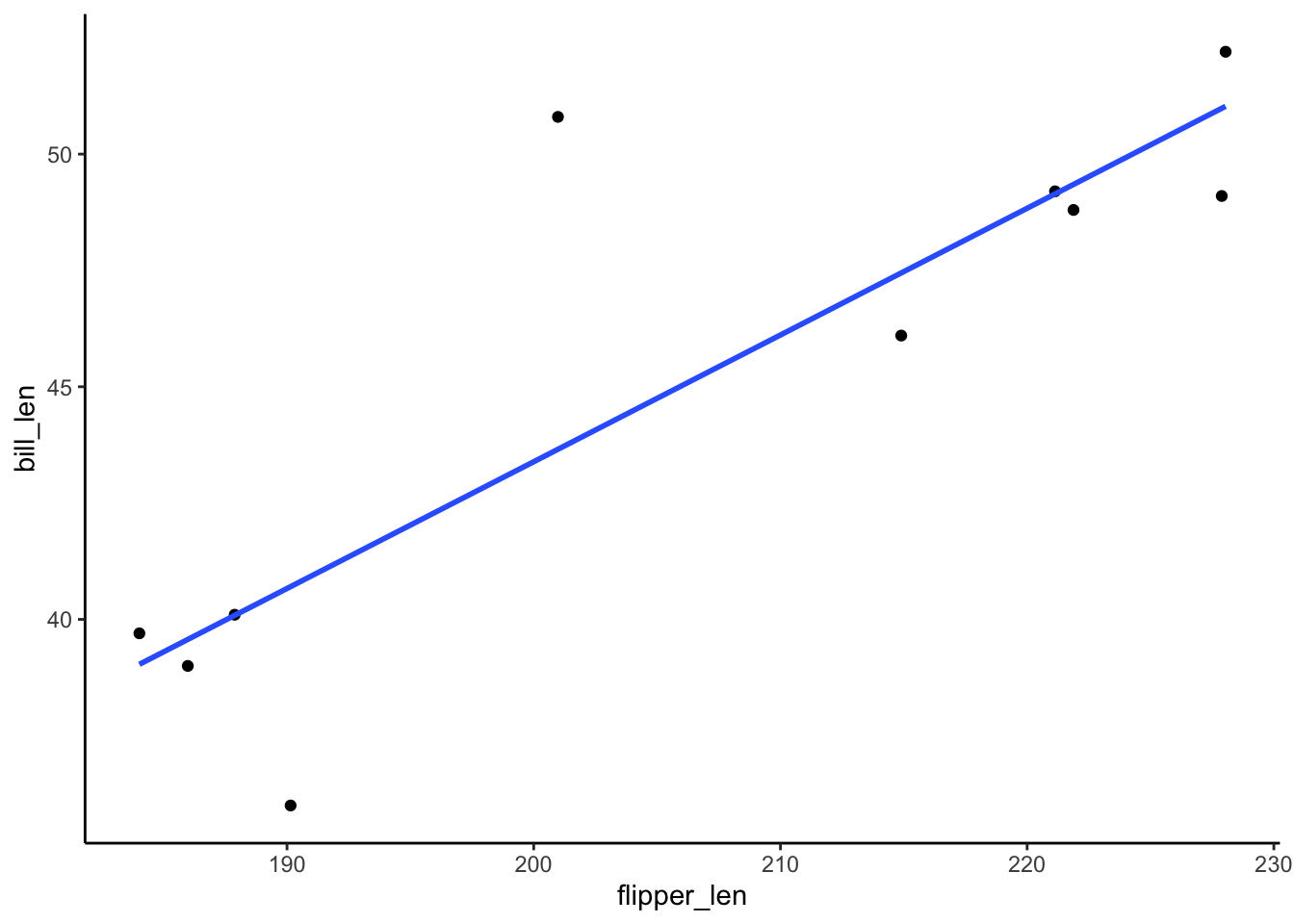
# A plot of model 2
ggplot(penguins_small, aes(y = bill_len, x = flipper_len)) +
geom_point() +
geom_smooth(method = "lm", formula = y ~ poly(x, 2), se = FALSE)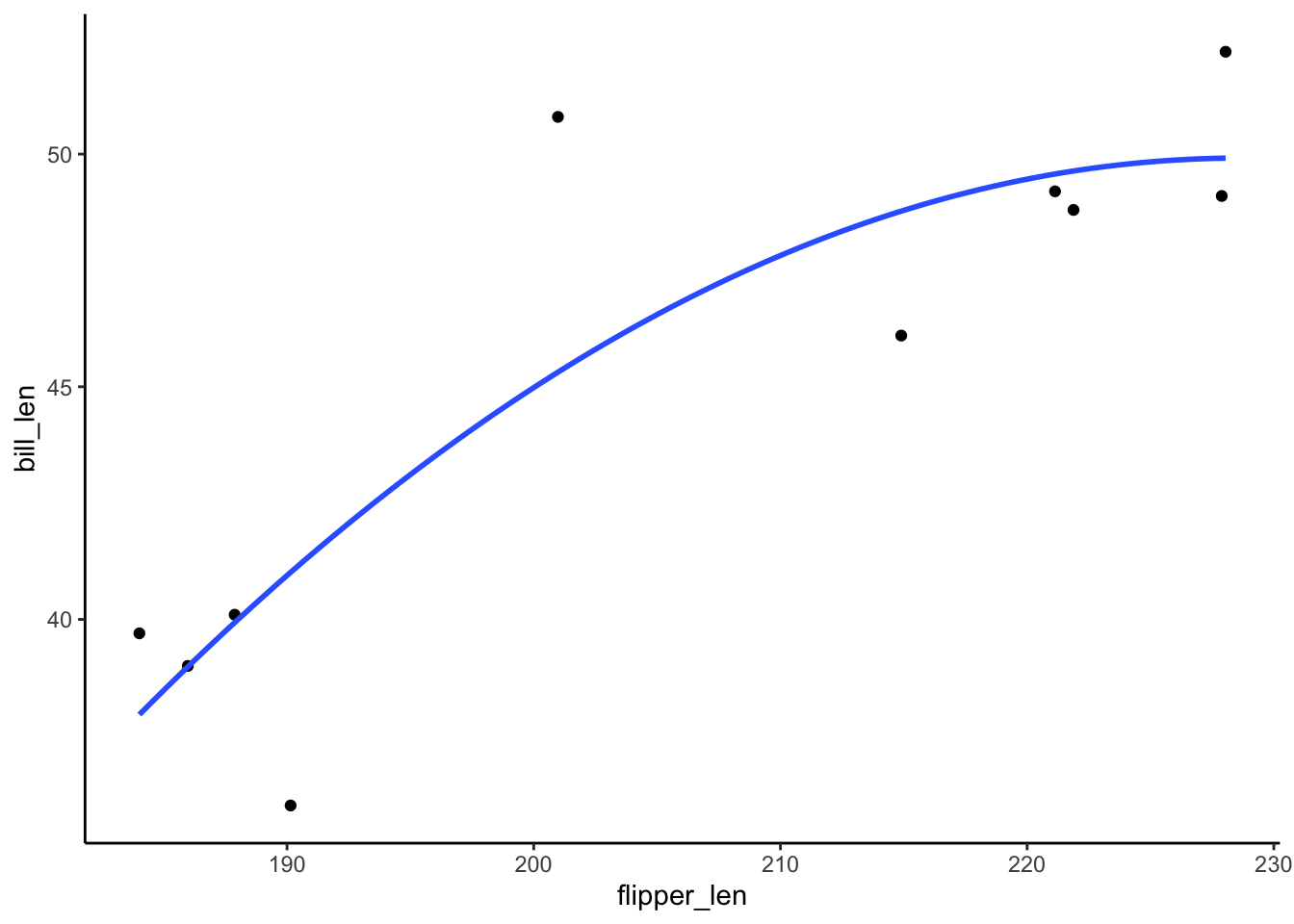
# A plot of model 9
ggplot(penguins_small, aes(y = bill_len, x = flipper_len)) +
geom_point() +
geom_smooth(method = "lm", formula = y ~ poly(x, 9), se = FALSE)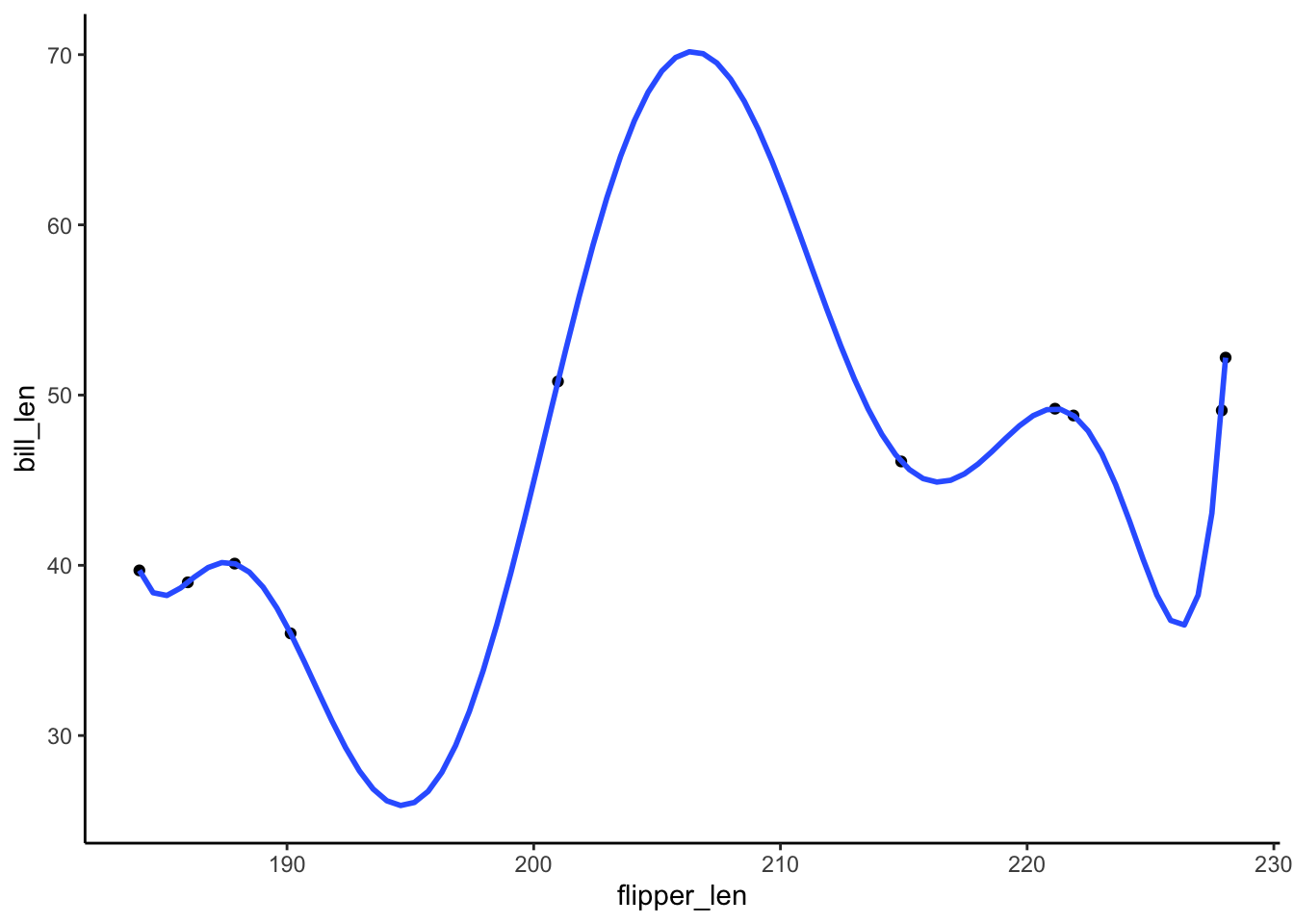
Exercise 5: Reflecting on these investigations
Solution
- salmon, chocolate, samosas. Together? Yuck!
- Regarding model 9:
- NOT easy to interpret.
- NO. It’s much more wiggly than the general trend.
- NOT WELL. It is too tailored to our data.
Exercise 6: Overfitting
Solution
- The model picks up the tiny details of our original sample (red dots) at the cost of losing the more general trends of the relationship of interest (as demonstrated by the black dots).
- The bottom left plot pokes fun at overfitting.
- funny.
Exercise 7: Questioning R-squared
Solution
It measures how well our model explains / predicts our sample data, not how well it explains / predicts the broader population. It also has the feature that any non-redundant predictor added to a model will increase the R-squared.
Exercise 8: Adjusted R-squared
Solution
- Adjusted R-squared is less than the R-squared
| Model | R-squared | Adj R-squared |
|---|---|---|
| bill_len ~ species | 0.7078 | 0.7061 |
| bill_len ~ species + island | 0.7085 | 0.7051 |
example_mod_1 <- lm(bill_len ~ species, penguins)
example_mod_2 <- lm(bill_len ~ species + island, penguins)
summary(example_mod_1)
Call:
lm(formula = bill_len ~ species, data = penguins)
Residuals:
Min 1Q Median 3Q Max
-7.9338 -2.2049 0.0086 2.0662 12.0951
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 38.7914 0.2409 161.05 <2e-16 ***
speciesChinstrap 10.0424 0.4323 23.23 <2e-16 ***
speciesGentoo 8.7135 0.3595 24.24 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.96 on 339 degrees of freedom
(2 observations deleted due to missingness)
Multiple R-squared: 0.7078, Adjusted R-squared: 0.7061
F-statistic: 410.6 on 2 and 339 DF, p-value: < 2.2e-16summary(example_mod_2)
Call:
lm(formula = bill_len ~ species + island, data = penguins)
Residuals:
Min 1Q Median 3Q Max
-7.9338 -2.2049 -0.0049 2.0951 12.0951
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 38.97500 0.44697 87.198 <2e-16 ***
speciesChinstrap 10.33204 0.53502 19.312 <2e-16 ***
speciesGentoo 8.52988 0.52082 16.378 <2e-16 ***
islandDream -0.47321 0.59729 -0.792 0.429
islandTorgersen -0.02402 0.61004 -0.039 0.969
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.965 on 337 degrees of freedom
(2 observations deleted due to missingness)
Multiple R-squared: 0.7085, Adjusted R-squared: 0.7051
F-statistic: 204.8 on 4 and 337 DF, p-value: < 2.2e-16- Adjusted R-squared is lower than R-squared
- From model 1 to 2, R-squared increased and Adjusted R-squared decreased.
islanddidn’t provide useful information about bill length beyond what was already provided by species.example_mod_1. The improvement to R-squared by addingislandto the model isn’t enough to offset the added complexity (Adj R-squared decreases).